일단 DJMAX와 Beat Saber를 선택한 이유는 리듬게임이며 집중도가 높은 게임이기 때문에 선택했다. BeatSaber의 경우 VR를 착용하고 하기 때문에 몰입이 될 수 있어서 집중도를 측정하기에 더 좋았다.
참고로 VR의 경우 VIVE PRO 1을 착용하고 했었다.
일단 영상 찍고 확인을 해보니.. 의외로 집중도가 낮게 나온다..
내가 이전 부터 이 기기를 테스트 하면서도 집중도가 확실히 낮게 나오기는 했었는데.. (ADHD인가..?)
DJMAX에서는 짧은 노트의 경우 집중도가 의외로 낮게 나온다. 그에 반면 긴 노트에서는 집중도가 높게 나왔다..
나도 게임을 클리어 하면서 짧은 노트들은 어느정도 칠 수 있어서 그나마 쉽게 넘어가는 반면 긴 노트의 경우 긴 노트를 눌르며 다른 노트들도 쳐야하다 보니 집중을 많이 하게 되는 것 같은데.. 심지어 지금도 그렇고 이때도 그렇고 장갑을 끼고 있다보니.. 더 키보드 치는 느낌이 잘 안들어서 저렇게 된 것 같다.
뭐 그래도 대부분 높게 나오기는 했다.
(장갑 끼는건 그냥 키보드 더러워질까봐.. 다한증..)
Beat Saber에서는 이상하게 전체적으로 낮게 나왔다..
이건 잘 모르겠다.. 내가 게임을 잘 못하는게 이것 때문인건가.. 하는 생각도 들긴 하는데..
일단 의심되는건.. 내 방이 덥다. 그래서 땀이 많이 나기도 하는데 그것 때문에 전극에 수분 때문에 전기가 잘 통해서 전극이 잘 요동치고 있다는 것을 알 수 있다. 이것 때문일 가능성도 있고.. 또 손을 엄청 움직이고 하기에 그 움직임도 같이 반영됬을 것으로 추정된다.. 또한 VR과 Muse 2를 같이 착용하고 측정하기 때문에 Muse 2가 제대로 측정이 안되었거나 VIVE PRO의 안면 폼이 방해했을 가능성이 있을 수 있다. 그리고 운동을 안해서인지.. FitBeat 하면서 다리를 굽혔다 피니깐.. 이후에 몇시간 동안 일어나거나 앉을려 하면 힘이 빠져서 움직이기도 어려울 정도였다.
그런데 그걸 제외해서라도 집중도가 낮은건 좀 이상하긴 하다.. 아니면 그냥 내가 게임에 집중을 잘 안했던 것일 수도 있고..
그리고 위에서도 말했지만 공통적으로 한가지 문제라면 Muse 2가 민감한건지 뭔지 자세를 움직인다거나 키보드를 친다거나 손을 많이 움직인다거나 이를 쎄게 닫는 경우 뇌파가 심하게 요동친다.. 이것 때문에 뇌파가 제대로 측정이 안되기도 한다. 그래도 모든 전극이 같이 반영되기 때문에 아마도 그에 따라서 바뀌니깐 딱히 상관은 없을 수도 있을 것 같다.
내가 이전 부터 인공지능이라고 말하기는 했지만.. 이번껀 머신러닝에 가깝다고 볼 수 있다.
보통 인공지능 하면 딥러닝을 생각하겠지만.. 여기서는 머신러닝이다.
뭐 인공지능 안에 머신러닝이 포함되어있으니 상관은 없겠지만..
이번에 적을 내용은 이전 글 보다는? 적을테고 쉬울 것이다.
대부분이 이미 만들어진 것을 쓰기 때문에..
하지만 자세하게 들어가면 역시 어렵긴 하지만.. 최대한 내가 이해한 배경으로 설명해보겠다..!
틀린 정보가 있을 수도 있다.. 작년인 대학교 1학년 때 했던 작업들이고.. 2~4개월 밖에 안했었기 때문에..
그리고.. 28일이 아닌 25 ~ 26일에 기기를 반납해야해서 서둘러야 한다..!!!
암튼 먼저 코드부터!
Brainflow ML로 집중도 구하는 코드 공유!
from time import sleep
from brainflow.board_shim import BoardShim, BrainFlowInputParams, BoardIds
from brainflow.data_filter import DataFilter
from brainflow.ml_model import MLModel, BrainFlowModelParams, BrainFlowMetrics, BrainFlowClassifiers
board_id = BoardIds.MUSE_2_BOARD
params = BrainFlowInputParams()
params.serial_number = "Muse-0465" # Muse 2의 고유 시리얼 넘버
board_shim = BoardShim(board_id, params)
use_data_seconds = 5 # n초 동안 데이터 수집
sampling_rate = BoardShim.get_sampling_rate(board_id)
eeg_channels = BoardShim.get_eeg_channels(board_id)
num_points = use_data_seconds * sampling_rate # 몇 초 동안의 데이터를 가져올지
# 머신러닝 모델 준비
mindfulness_params = BrainFlowModelParams(BrainFlowMetrics.MINDFULNESS, BrainFlowClassifiers.DEFAULT_CLASSIFIER)
mindfulness = MLModel(mindfulness_params)
mindfulness.prepare()
# Muse 2 연결
board_shim.prepare_session()
# Muse 2 데이터 수집 시작
board_shim.start_stream()
# n초 + 1초 동안 데이터 수집
sleep(use_data_seconds + 1)
# 수집한 데이터를 변수에 저장
data = board_shim.get_current_board_data(num_points)
# 예측에 필요한 데이터 추출
bands = DataFilter.get_avg_band_powers(data, eeg_channels, sampling_rate, True)
feature_vector = bands[0]
# 집중도 예측
print(f"Mindfulness: {mindfulness.predict(feature_vector)[0]}")
# 모델 해제
mindfulness.release()
# Muse 2 데이터 수집 정지
board_shim.stop_stream()
# Muse 2 연결 해제
board_shim.release_session()
이번엔 아마도 저번보다는 쉽지 않을까 한다.. 코드적인걸로는..
이전 글에 대부분의 내용들을 넣어놓은거라서..
지금 새벽 4시 40분인데 다 쓰고 나면 짧겠지..? 라 생각 중..
참고로 이전 글에서 말했던 것 처럼 Mindfulness를 썼던게 Brainflow에서 Mindfulness로 썼어서 그걸로 쓴거다..
암튼 그렇다..
코드 설명 및 이해하기
설명할 수록 점점 코드 설명할게 적어져서 좋긴 하다.
전 글에서 한가지 안쓴게 있다면 필요한 라이브러리를 불러오는 것에 대해 안적었는데.. 뭐 간단한거니 여기서도 안적겠다!
코드에서는 모델과 분류기를 정하고 정한 파라미터로 모델을 할당해서 모델을 쓸 수 있도록 활성화 시키는 코드이다.
일단 Brainflow에선 기본적으로 어떤 모델과 분류기가 가능한지 아는 것이 좋다.
그러기 위해선 BrainFlowMetrics, BrainFlowClassifiers 정의 코드를 살펴봐야 한다.. 코드를 보면
# 코드 설명을 하기 위한 코드
class BrainFlowMetrics(enum.IntEnum):
"""Enum to store all supported metrics"""
MINDFULNESS = 0 #:
RESTFULNESS = 1 #:
USER_DEFINED = 2 #:
class BrainFlowClassifiers(enum.IntEnum):
"""Enum to store all supported classifiers"""
DEFAULT_CLASSIFIER = 0 #:
DYN_LIB_CLASSIFIER = 1 #:
ONNX_CLASSIFIER = 2 #:
이런식으로 정의가 되어있다.
참고로 BrainFlowMetrics는 모델이 어떤 역할을 할지 선택하는 것이고, BrainFlowClassifiers는 그 역할을 계산할 수 있는 분류기를 선택할 수 있도록 하는 것이다.
각각에 대해서 설명하자면
BrainFlowMetrics
MINDFULNESS : 마음챙김, 집중도와 비슷할 순 있지만 좀 다른 것, 현재 자연스럽게 어느정도 집중 했는지
RESTFULNESS : 휴식상태, 어느정도 휴식 상태인지
USER_DEFINED : 사용자가 직접 정의
BrainFlowClassifiers
DEFAULT_CLASSIFIER : 기본 분류기 (MINDFULNESS, RESTFULNESS 사용할 때)
DYN_LIB_CLASSIFIER : .dll, .so 같은 C/C++로 만든 알고리즘을 적용하고 싶을 때
ONNX_CLASSIFIER : ONNX 모델을 사용할 때 (USER_DEFINED 사용할 때)
여기에서 예시로 들 것은 Mindfulness이다. 설명을 적어놓기는 했지만 사실 나도 잘은 이해 못했다. 솔직히 저 설명으론 부족해서 추가로 말하자면, 내가 어느 순간에 공부나 무언가를 뚫어져라 보면서 갑자기 집중하는 것이 아닌.. 자연스럽게 무언가의 변화 등으로 자연스럽게 그것에 관심을 기울이는 것을 말하는 것 같다.
예를 들면 이전에서 한 Attention은 한 곳을 뚫어져라 바라볼 때 지표가 올라가고
Mindfulness는 밥 먹다가 수저가 바닥으로 떨어지며 그 소리에 기울인다 생각하면 된다.
수업 자료를 만들 때는 Mindfulness로 집중도를 구해서 게임할 수 있도록 했었는데.. 이젠 수정해야할 것 같다.. 하하하..
만약 이전 글에서 말한 수식으로 모델을 만든다면 집중하거나 안하는 데이터를 모두 수집한 후 수식으로 계산시키고 정규화 시킨 후에 학습시켜서 사용자 정의 모델로 등록하면 될 것 같긴 하다. (Brainflow에 등록 요청해볼까 생각중..)
기본 분류기는 아마도 Mindfulness나 Restfulness를 계산하는데만 쓰는 것 같다. 이에 대한건 predict 부분에서 더 자세하게 얘기할 것이다.
ONNX 분류기는 User_Defined로 선택했을 때 쓸 수 있는 것 같은데, 직접 Python으로 모델을 학습해서 만든 모델을 적용할 수 있도록 해주는 것이다. 이 분류기를 제작하는건 내가 반납 전에 쓸 분량을 다 쓰고 시간이 남는다면 써보고.. 안되면 아래에 링크한 튜토리얼을 보고 하면 될 것 같다.
추가로 여기서 한가지 생각이 들 것이다. 모델을 직접 정의할 수 있으면 BrainFlowMetrics는 왜 있는걸까? 라는 생각을 할 수 있다. 나도 제대로는 모르겠지만.. 내가 생각하기에는 Mindfulness랑 Restfulness를 쓸 수 있도록 하기 위해서 인 것 같다. 오픈소스다 보니 코드를 직접 수정할 수도 있는데 거기에서 추가적인 모델을 넣을 수 있도록 하거나 나중에 추가하기 위해서 저렇게 구분한 것 같다고 생각이 든다.
아무튼 여기에서는 Mindfulness를 계산하고 이 때문에 Default Classifier를 사용하게 된다.
# 예측에 필요한 데이터 추출
bands = DataFilter.get_avg_band_powers(data, eeg_channels, sampling_rate, True)
feature_vector = bands[0]
# 집중도 예측
print(f"Mindfulness: {mindfulness.predict(feature_vector)[0]}")
위에 2줄은 이전에 설명했기 때문에 패스하고
여기에서 볼 것은 저 아래 출력문이다.. 이전에 할당한 Mindfulness 모델에 수집한 데이터의 평균 파워를 넣어 예측하게 하는 코드이다.
즉 이전 글에서 설명한 평균의 Delta, Theta, Alpha, Beta, Gamma 값을 넣어 예측시키는 코드라고 보면 된다.
그런데 또 의문이 들것이다. 왜 예측한 것의 0번 인덱스 값을 가져오라고 하는지.. 일단 확인해보니 0번 인덱스 외의 값은 없다. 그런데 리스트로 반환하는 이유가 뭔지 생각해보니.. 아마도 다른 사용자 정의 분류기를 사용하게 되면 여러 값을 리턴해야하는 경우가 있을테니 그것 때문인 듯 하다.
아무튼 리스트로 반환되기 때문에 [값] 이런식으로 출력되지 않게 하기 위해 0 인덱스로 접근해서 데이터를 가져와 출력하게 되어있다.
참고로 찾으면서 방금 발견한게 있는데.. 수업 자료를 만들 때는 저거를 1초나 2초로 했었다..
그런데 갑자기 최소 몇초를 해야하는 생각이 들어서 더 찾아봤는데.. 당시에는 못 찾은 주석이 있었다..
# recommended window size for eeg metric calculation is at least 4 seconds, bigger is better
음.. EEG로 어떤 것을 계산해야한다면 4초 이상의 데이터는 필요하다고.. 한다.. 클 수록 좋다고 하고.. 흐음..
수업 자료를 고쳐서 다시 교수님께 드려야 할 것 같다는 생각이 든다.. 하하;;
그럼 Mindfulness의 계산 방법에 대해 궁금한점이 생길 것이다.
위에서 말했듯이 머신러닝이다. 하지만 더 자세히 보기 위해 코드로 보겠다!
# 코드 설명을 하기 위한 코드
# src/ml/generated/mindfulness_model.cpp
const double mindfulness_coefficients[5] = {-1.4060899708538128,2.597693987367105,-30.96470526503066,12.04593986553724,45.773017975354556};
double mindfulness_intercept = 0.000000;
# 코드 설명을 하기 위한 코드
# src/ml/mindfulness_classifier.cpp
int MindfulnessClassifier::predict (double *data, int data_len, double *output, int *output_len)
{
if ((data_len < 5) || (data == NULL) || (output == NULL))
{
safe_logger (spdlog::level::err,
"Incorrect arguments. Null pointers or invalid feature vector size.");
return (int)BrainFlowExitCodes::INVALID_ARGUMENTS_ERROR;
}
double value = 0.0;
for (int i = 0; i < std::min (data_len, 5); i++)
{
value += mindfulness_coefficients[i] * data[i];
}
double mindfulness = 1.0 / (1.0 + exp (-1.0 * (mindfulness_intercept + value)));
*output = mindfulness;
*output_len = 1;
return (int)BrainFlowExitCodes::STATUS_OK;
}
이게 Mindfulness를 계산하는 코드이다. Python이 아닌 이유는 Brainflow는 C++로 만든걸 Python에 이식한 것이기 때문이다.. 저건 메인 C++에 있는 코드..
하나씩 보자면 일단 mindfulness_coefficients, mindfulness_intercept 이거는 인공지능을 어느정도 했었다면 알 수 있다.
이런 과정으로 계산되게 된다. 결론적으로 내부적으로 계산된 값인 0.33481021과 비교하면 반올림되서 잘린거 빼고는 결과값의 차이는 없다. 그렇다는건 위 계산 과정이 맞다는 것이 되니 저걸 보면 된다!
아무튼 계산 과정이 이렇다. 어떻게 보면 간단할 수도 있고 복잡할 수도 있다.
참고로 DNN(깊은 신경망)은 저런 계산하는 것이 겁나게 많은 것 뿐이다.
당시 수업 자료 만들 때의 PPT에 내가 만들어둔 사진이다. 아래 사진을 보면 이해가 더 쉬울지도 몰라서 올려놓겠다.
지금 봤는데.. 가중치 값이 업데이트 되었나보다.. 사진에 있는건 대략 5개월 전의 가중치 값..
참고로 재미있는점이 한가지 있는데.. Restfulness를 계산하는 과정이다..
예전에도 찾았었던 것 같은데.. 지금봐도 어이가 없다.
# 코드 설명을 하기 위한 코드
# src/ml/inc/restfulness_classifier.h
#pragma once
#include "brainflow_constants.h"
#include "mindfulness_classifier.h"
class RestfulnessClassifier : public MindfulnessClassifier
{
public:
RestfulnessClassifier (struct BrainFlowModelParams params) : MindfulnessClassifier (params)
{
}
int predict (double *data, int data_len, double *output, int *output_len)
{
int res = MindfulnessClassifier::predict (data, data_len, output, output_len);
if (res != (int)BrainFlowExitCodes::STATUS_OK)
{
return res;
}
*output = 1.0 - (*output);
return res;
}
};
안믿을 것 같아서 Restfulness의 전체 코드를 가져왔다.
해석해보면 MindfulnessClassifier를 할당 받아서 MindfulnessClassifier에 있는 예측하는 코드로 예측시킨 후
그 값을 (1.0 - 값) 이걸로 계산한다는 것이다.
즉 (1.0 - Mindfulness 예측 값)이다. 이 말은 Restfulness는 Mindfulness의 반대 값이라고 생각하면 될 것 같다..
그래서 더 해보면 1이 나오는걸 알 수 있다.
암튼 저런 계산 과정으로 마음챙김도가 나오는 것이다.
저런 마음 챙김 모델도 학습하는 방법도 나와있는데 그건 맨 아래 링크에 달아두었다.
mindfulness.release()
위에서 할당한 모델을 해제하는 것이다.
암튼 이제 설명을 다 했으니 코드를 실행해봐야 한다. (위에서 이미 실행한 결과는 무시하시길..)
코드 실행
[2025-02-21 09:47:34.717] [board_logger] [info] incoming json: {
"file": "",
"file_anc": "",
"file_aux": "",
"ip_address": "",
"ip_address_anc": "",
"ip_address_aux": "",
"ip_port": 0,
"ip_port_anc": 0,
"ip_port_aux": 0,
"ip_protocol": 0,
"mac_address": "",
"master_board": -100,
"other_info": "",
"serial_number": "Muse-0465",
"serial_port": "",
"timeout": 0
}
[2025-02-21 09:47:34.717] [board_logger] [info] Use timeout for discovery: 6
[INFO] SimpleBLE: D:\a\brainflow\brainflow\third_party\SimpleBLE\simpleble\src\backends\windows\Utils.cpp:33 in initialize_winrt: CoGetApartmentType: cotype=-1, qualifier=0, result=800401F0
[INFO] SimpleBLE: D:\a\brainflow\brainflow\third_party\SimpleBLE\simpleble\src\backends\windows\Utils.cpp:41 in initialize_winrt: RoInitialize: result=0
[2025-02-21 09:47:34.764] [board_logger] [info] found 1 BLE adapter(s)
[2025-02-21 09:47:34.958] [board_logger] [info] Found Muse device
[2025-02-21 09:47:36.400] [board_logger] [info] Connected to Muse Device
[2025-02-21 09:47:37.405] [board_logger] [info] found control characteristic
Mindfulness: 0.97519466
이런식으로 뜬다. 로그 정보들은 이전에도 설명한 것과 같이 똑같으니 무시하고
"Mindfulness: 0.97519466" 값만 보면 된다.
다만 전에 이 집중도하고 전 글의 집중도하고 다르긴 하지만 비슷하기 때문에 자세하게 측정결과는 작성 안할 것이다.
어차피.. 내가 설명한 여기에서의 Mindfulness 집중도는.. 나도 잘 만들어내기가 어렵다..
참고로 Restfulness는 Mindfulness를 전부 Restfulness로 바꾸면 된다.
그럼으로 이번 글은 여기에서 끝내는걸로..
추가로 이전 글에서도 올린 것 처럼 실시간으로 돌릴 수 있는 코드!
import keyboard
from time import sleep
from brainflow.board_shim import BoardShim, BrainFlowInputParams, BoardIds
from brainflow.data_filter import DataFilter
from brainflow.ml_model import MLModel, BrainFlowModelParams, BrainFlowMetrics, BrainFlowClassifiers
board_id = BoardIds.MUSE_2_BOARD
params = BrainFlowInputParams()
params.serial_number = "Muse-0465" # Muse 2의 고유 시리얼 넘버
board_shim = BoardShim(board_id, params)
use_data_seconds = 5 # n초 동안 데이터 수집
sampling_rate = BoardShim.get_sampling_rate(board_id)
eeg_channels = BoardShim.get_eeg_channels(board_id)
num_points = use_data_seconds * sampling_rate # 몇 초 동안의 데이터를 가져올지
# 머신러닝 모델 준비
mindfulness_params = BrainFlowModelParams(BrainFlowMetrics.MINDFULNESS, BrainFlowClassifiers.DEFAULT_CLASSIFIER)
mindfulness = MLModel(mindfulness_params)
mindfulness.prepare()
# Muse 2 연결
board_shim.prepare_session()
# Muse 2 데이터 수집 시작
board_shim.start_stream()
# n초 + 1초 동안 데이터 수집 - 안하면 오류남
sleep(use_data_seconds + 1)
while True:
# 나가기 조건
if keyboard.is_pressed('q'):
break
# 수집한 데이터를 변수에 저장
data = board_shim.get_current_board_data(num_points)
# 예측에 필요한 데이터 추출
bands = DataFilter.get_avg_band_powers(data, eeg_channels, sampling_rate, True)
feature_vector = bands[0]
# 집중도 예측
print(f"Mindfulness: {mindfulness.predict(feature_vector)[0]}")
# 모델 해제
mindfulness.release()
# Muse 2 데이터 수집 정지
board_shim.stop_stream()
# Muse 2 연결 해제
board_shim.release_session()
이제 올릴려 한 것들은 다 올렸고.. 추가로 나머지는 인공지능을 만들어서 적용해보거나 게임을 하면서 집중도는 어떤지 측정해서 올려볼려고 한다.
그리고 조금 문제가 생겼다.. 당시에는 EEG를 알아내고 brainflow를 C++로도 사용하고 Python으로도 사용해서 집중도나 이런 거 구하는 거를 했었는데.. 학교를 다니면서 기숙사에서 작업하다 보니 정신이 별로 없던 것 같다.. 2~4주 안에 이 모든 걸 다 했으니..
그렇다 보니 지금 다시 확인해 봤는데 코드가 좀 엉망이다.. 잘못된 정보들이 대부분일 수 있다.
최대한으로 찾아서 해보고 있지만 코드적인 실수가 어디선가 있을 수도 있긴 하다..
참고로 대학교 수업 자료로 쓴 것이기에.. 잘못 정보를 전달했다는 걸 지금 느꼈다..
솔직히 어디서부터 써야 될지 감이 안 잡히긴 하는데.. 어떻게든 적어보겠다..
아무튼 시작!
집중도 구하는 코드 먼저!
from time import sleep
from brainflow.board_shim import BoardShim, BrainFlowInputParams, BoardIds
from brainflow.data_filter import DataFilter, FilterTypes
board_id = BoardIds.MUSE_2_BOARD
params = BrainFlowInputParams()
params.serial_number = "Muse-0465" # Muse 2의 고유 시리얼 넘버
board_shim = BoardShim(board_id, params)
use_data_seconds = 1 # n초 동안 데이터 수집
sampling_rate = BoardShim.get_sampling_rate(board_id)
eeg_channels = BoardShim.get_eeg_channels(board_id)
num_points = use_data_seconds * sampling_rate # 몇 초 동안의 데이터를 가져올지
# Muse 2 연결
board_shim.prepare_session()
# Muse 2 데이터 수집 시작
board_shim.start_stream()
# n초 + 1초 동안 데이터 수집
sleep(use_data_seconds + 1)
# 수집한 데이터를 변수에 저장
data = board_shim.get_current_board_data(num_points)
# 데이터 처리
for count, channel in enumerate(eeg_channels):
DataFilter.perform_bandpass(data[channel], sampling_rate, 2.0, 45.0, 4, FilterTypes.BESSEL_ZERO_PHASE, 0) # 분석할 파형 밖의 범위 제거
DataFilter.perform_bandstop(data[channel], sampling_rate, 48.0, 52.0, 4, FilterTypes.BUTTERWORTH_ZERO_PHASE, 0) # 50Hz의 주변 전기 노이즈 제거
DataFilter.perform_bandstop(data[channel], sampling_rate, 58.0, 62.0, 4, FilterTypes.BUTTERWORTH_ZERO_PHASE, 0) # 60Hz의 주변 전기 노이즈 제거
# 예측에 필요한 데이터 추출
bands = DataFilter.get_avg_band_powers(data, eeg_channels, sampling_rate, False)
feature_vector = bands[0]
# 집중도 예측
print(f"Attention: {feature_vector[3] / feature_vector[2]}") # Beta / Alpha
# Muse 2 데이터 수집 정지
board_shim.stop_stream()
# Muse 2 연결 해제
board_shim.release_session()
이번 코드는 이것이다.
최대한 이해하기 쉽게 하기 위해 이전 코드에서 데이터 처리 부분만 추가해서 작동하도록 했다.
그렇다 보니 코드 설명에선 이전에 한 부분은 제외하고 하겠다..
참고로 저번에 데이터를 확인했기 때문에 여기에선 집중도만 구할 것이기에 데이터를 저장하는 코드는 넣지 않았다.
넣고 싶으면 이전 코드에서 가져와서 넣길..
그리고 이번에는 n초로 주석이 되어있다. 이유라면 집중도를 측정하기 때문에 1초 정도로는 부족한 것 같아서 5초로 했다. 하지만 저건 변경할 수도 있으니 n초로 한 것
코드 설명 전 이해할 것
뇌파로 분석을 할 때 보통 사용되는 특정 주파수의 파형이 있다. (바로 아래 사진)
(바로 아래 사진 말고 그 사진 아래 있는 사진은 한국어로 되어있으니 그걸 먼저 보는 것을 추천합니다.)
그 파형은Delta(델타), Theta(세타), Alpha(알파), Beta(베타), Gamma(감마)인데 위의 Muse 공식 사이트 안에 설명되어 있는 내용 중 사진에서 가져온 걸 보면 된다.
수집된 데이터에서 FFT(고속 푸리에 변환) 방법으로 저렇게 특정 파형을 뽑아낼 수 있다.
각 파형은 각각의 특색이 있다. 그 특색은 사진의 오른쪽에 적혀있다. 그냥 현재 뇌의 상태를 알 수 있는 파형이라 생각하면 된다.
뭐 잠든 건지 깨어있는지 집중도가 강한지 등을 알 수 있게 된다.
아무튼 저런 파형은 적혀있는 대로 Delta(0.5, 4.0), Theta(4.0, 8.0), Alpha(8.0, 13.0), Beta(13.0, 32.0), Gamma(32.0, 100.0) 이런 범위로 되어있다. 저 범위에 있는 걸 추출하면 현재 뇌 상태를 알 수 있다는 의미? 가 된다.
어디서는 0.5에서 델타가 시작하고 어디에서는 3.5에서 시작하고 어디에서는 2로 시작하고 그런다..
암튼 저 범위는 무시하고 그냥 각각 파형에 따라 그 파형이 무슨 역할을 하는지만 이해하면 될 것 같다.
참고로 아래에서 말하겠지만 집중도 구할 때 사용하는 파형은 베타파와 알파파이다.
코드 설명 및 이해하기
use_data_seconds = 1 # n초 동안 데이터 수집
sampling_rate = BoardShim.get_sampling_rate(board_id)
eeg_channels = BoardShim.get_eeg_channels(board_id)
num_points = use_data_seconds * sampling_rate # 몇 초 동안의 데이터를 가져올지
이전 글에서 설명한 코드에 추가적으로 eeg_channels에 대한게 있어서 그것만 추가로 적어보겠다.
지금은 코드를 정상적으로 고쳤는데.. 저기 뒤에 get_avg_band_powers 함수의 뒤에 False인 부분을 처음에는 True로 했었다. True로 하게 되면 저게 Apply Filter인데 바로 위에 데이터 처리 코드 부분을 수행한 뒤에 데이터를 반환해 준다..
즉 지금은 False로 해서 위에서 전처리한 게 소용이 있는데.. True로 하면 전처리를 하고 또 전처리를 하게 되어서 좀 별로다.. 암튼 그럼..
이 코드는 수집된 데이터에서 Delta(델타), Theta(세타), Alpha(알파), Beta(베타), Gamma(감마) 데이터(band_powers)를 뽑아서 그중 평균값만 뽑아 feature_vector에 저장하는 코드이다. (위에 파형에 대한 설명을 적어놓았으니 델타 세타파 저런 게 뭔지 모르겠다면 위에 적은 걸 보시길..)
그리고 feature_vector에는 bands[0]을 저장하는데 위에 적혀있는 것처럼 평균값만 뽑는다.
그럼 bands에 저장되어 있는 다른 건 무엇이냐.. 하면.. get_avg_band_powers가 뭘 리턴하는지 보면 된다.
# 코드 설명을 하기 위한 코드
def get_avg_band_powers(cls, data, channels: List, sampling_rate: int, apply_filter: bool) -> Tuple:
"""calculate avg and stddev of BandPowers across all channels, bands are 1-4,4-8,8-13,13-30,30-50
:param data: 2d array for calculation
:type data: NDArray[Shape["*, *"], Float64]
:param channels: channels - rows of data array which should be used for calculation
:type channels: List
:param sampling_rate: sampling rate
:type sampling_rate: int
:param apply_filter: apply bandpass and bandstop filtrers or not
:type apply_filter: bool
:return: avg and stddev arrays for bandpowers
:rtype: tuple
"""
bands = [(2.0, 4.0), (4.0, 8.0), (8.0, 13.0), (13.0, 30.0), (30.0, 45.0)]
return cls.get_custom_band_powers(data, bands, channels, sampling_rate, apply_filter)
이게 그 함수의 코드이다.
아래 bands에 정의되어 있는 건 Delta, Theta, Alpha, Beta, Gamma 파형의 범위 값이다. 위에서 말했듯이 여기에서 사용하는 파형의 범위도 약간 다르다.
아무튼 코드 보단 주석을 보면 되는데..
주석을 보면 return이 뭐를 반환하는지 적혀있다.
avg는 평균값을 의미하고 stddev는 표준편차를 의미한다. 배열로 2가지 값들을 반환하기 때문에 0번 인덱스인 평균값만 불러오도록 코드를 제작한 것이다.
참고로 분석에는 보통 평균값을 이용하고 데이터의 안전성이나 변동성을 확인할 때는 표준편차를 이용한다 한다.
그리고 리턴되는건 Delta, Theta, Alpha, Beta, Gamma 각각의 평균 값과 표준편차 값이다. 즉 입력된 모든 데이터의 5개 뇌파가 나오는게 아니라 모든 전극 뇌파에서 Delta, Theta, Alpha, Beta, Gamma를 추출하고 그것으로 평균과 표준편차 값을 구해서 반환한 것이다. 그래서 리턴되는 것에서 평균과 표준편차 각각은 5개의 실수가 리스트로 담겨서 리턴된다.
추가적으로 원하는 범위를 사용하여 추출하고 싶으면 저기 return 부분에 적혀있는 것처럼 get_custom_band_powers 이 함수에 원하는 범위를 담은 리스트를 넘겨서 받아내면 된다. (난 잘 모르기에 brainflow에서 사용하는 걸 사용)
추가적으로 위에 왜 함수 사용할 때 False로 해놓았냐에 대한 설명이 있는데.. 그걸 좀 더 자세하게 설명해 보면..
저 apply_filter가 어디에서 사용되는지 따라가 봤다. 따라가 봤는데 DataHandlerDLL의 함수에 사용된다고 한다.. DLL를 본 순간.. 이 brainflow는 C++로 제작된 거니깐 C++ 코드에 있겠다 생각하고 C++ 코드를 찾아보았다..
그리고 찾아냈는데.. 아래 C++ 코드가 있었다.
# 코드 설명을 하기 위한 코드
if (apply_filters)
{
exit_codes[i] = detrend (thread_data, cols, (int)DetrendOperations::CONSTANT);
if (exit_codes[i] == (int)BrainFlowExitCodes::STATUS_OK)
{
exit_codes[i] = perform_bandstop (thread_data, cols, sampling_rate, 48.0, 52.0, 4,
(int)FilterTypes::BUTTERWORTH_ZERO_PHASE, 0.0);
}
if (exit_codes[i] == (int)BrainFlowExitCodes::STATUS_OK)
{
exit_codes[i] = perform_bandstop (thread_data, cols, sampling_rate, 58.0, 62.0, 4,
(int)FilterTypes::BUTTERWORTH_ZERO_PHASE, 0.0);
}
if (exit_codes[i] == (int)BrainFlowExitCodes::STATUS_OK)
{
exit_codes[i] = perform_bandpass (thread_data, cols, sampling_rate, 2.0, 45.0, 4,
(int)FilterTypes::BUTTERWORTH_ZERO_PHASE, 0.0);
}
}
봤을 때 바로 알 수 있을 것이다.. 이 코드 설명 바로 위 코드 설명에 있는 코드하고 닮았다..
즉 apply_filter를 켜게 되면 위에서 했던 데이터 처리 코드가 작동한다는 것..
그 때문에 apply_filter를 켜면 데이터 처리를 했는데 또 처리를 하게 된다는 의미..
뭐 그래도 약간은 달라서 괜찮을지도..?
(근데 함수와 괄호 사이가 왜 띄어져 있는 거지? brainflow 코드 살펴보면서 제일 신경 쓰이는 것..)
원래는 저걸 Attention이라 안 적고 Mindfulness 라 적었는데.. 이유는 다음 글에서 설명할 인공지능으로 집중도 구하는 것과 관련되어 있는데.. 거기에서는 Mindfulness를 사용한다.. 그런데 저 Beta / Alpha 이게.. 집중도를 구하는데 Mindfulness 보단 Attention으로 번역하는 게 더 맞아서 수정했다. 그리고 찾아보니 다음 글에서 할 Mindfulness는 현재의 집중도와 약간 다르긴 하다.. 뭐 딱히 중요하진 않으니 넘어가도 괜찮지 않을까라는.. 생가..ㄱ
암튼 저거 위에서 가져온 feature_vector 변수에는 어쨌든 평균값의 델타 베타 이런 값들이 가져와지게 되는데
거기에서 순서대로 델타부터 해서 해보면..
Delta(델타) : feature_vector[0]
Theta(세타) : feature_vector[1]
Alpha(알파) : feature_vector[2]
Beta(베타) : feature_vector[3]
Gamma(감마) : feature_vector[3]
이렇게 인덱싱할 수 있다고 생각하면 된다.
그렇기에 3번과 2번을 가져와서 나누는 거니깐 암튼 Beta / Alpha를 한다는 소리..
이걸 하면 집중도가 구해진다는 의미가 된다.
저 Beta / Alpha 수식은 보통적으로 집중도를 구할 때 많이 사용되는 수식 같다. 솔직히 나는 저게 집중도를 구할 수 있는 건지는 잘 모르겠다. 뭐 그래도 아래에 Beta / Alpha가 언급된 논문 2개를 걸어놓겠다.. (참고로 영어라서 거의 보진 않았다..)
from time import sleep
from brainflow.board_shim import BoardShim, BrainFlowInputParams, BoardIds
from brainflow.data_filter import DataFilter
board_id = BoardIds.MUSE_2_BOARD
params = BrainFlowInputParams()
params.serial_number = "Muse-0465" # Muse 2의 고유 시리얼 넘버
board_shim = BoardShim(board_id, params)
use_data_seconds = 5 # n초 동안 데이터 수집
sampling_rate = BoardShim.get_sampling_rate(board_id)
eeg_channels = BoardShim.get_eeg_channels(board_id)
num_points = use_data_seconds * sampling_rate # 몇 초 동안의 데이터를 가져올지
# Muse 2 연결
board_shim.prepare_session()
# Muse 2 데이터 수집 시작
board_shim.start_stream()
# n초 + 1초 동안 데이터 수집
sleep(use_data_seconds + 1)
# 수집한 데이터를 변수에 저장
data = board_shim.get_current_board_data(num_points)
# 예측에 필요한 데이터 추출
bands = DataFilter.get_avg_band_powers(data, eeg_channels, sampling_rate, True)
feature_vector = bands[0]
# 집중도 예측
print(f"Attention: {feature_vector[3] / feature_vector[2]}") # Beta / Alpha
# Muse 2 데이터 수집 정지
board_shim.stop_stream()
# Muse 2 연결 해제
board_shim.release_session()
이 코드는 위에서 말했듯이 get_avg_band_powers에서 자동으로 필터 적용해 주는 apply_filter를 켜서 데이터 전처리를 따로 안 하고 되도록 하는 코드이다.
위에 코드는 잊어버리고 이거 사용하면 될 듯하다..
암튼 바로 실행해 보자! 이번엔 귀찮긴 하지만 착용하고 측정했다!
그리고 위에서도 말했듯이 이번에는 1초가 아니라 5초 측정이다.
1초로도 되기는 하는데.. 조금 부족해 보여서 5초로 했고.. 좀 더 길게 할수록 정확도는 높아질 것 같다 생각은 들긴 한다..
코드 실행!
[2025-02-19 07:46:39.169] [board_logger] [info] incoming json: {
"file": "",
"file_anc": "",
"file_aux": "",
"ip_address": "",
"ip_address_anc": "",
"ip_address_aux": "",
"ip_port": 0,
"ip_port_anc": 0,
"ip_port_aux": 0,
"ip_protocol": 0,
"mac_address": "",
"master_board": -100,
"other_info": "",
"serial_number": "Muse-0465",
"serial_port": "",
"timeout": 0
}
[2025-02-19 07:46:39.170] [board_logger] [info] Use timeout for discovery: 6
[INFO] SimpleBLE: D:\a\brainflow\brainflow\third_party\SimpleBLE\simpleble\src\backends\windows\Utils.cpp:33 in initialize_winrt: CoGetApartmentType: cotype=-1, qualifier=0, result=800401F0
[INFO] SimpleBLE: D:\a\brainflow\brainflow\third_party\SimpleBLE\simpleble\src\backends\windows\Utils.cpp:41 in initialize_winrt: RoInitialize: result=0
[2025-02-19 07:46:39.203] [board_logger] [info] found 1 BLE adapter(s)
[2025-02-19 07:46:39.409] [board_logger] [info] Found Muse device
[2025-02-19 07:46:41.070] [board_logger] [info] Connected to Muse Device
[2025-02-19 07:46:42.072] [board_logger] [info] found control characteristic
Attention: 0.5993206298011964
다른 정보 출력들은 이전 글에서 말했으니 무시하고 Attention만 봐보자!
처음 실행하고 코드의 한 함수를 보면서 집중했을 때 (글 쓰느라 머리 엄청 아픈 상태였음 글 쓰는데 6시간쯤 됐을 때)
Attention: 1.172955634748009
값이 작아지나 머리 흔들거나 집중 안 했을 때 (딴 데 보거나 머리 흔듦.. 집중해서 머리 아픈 상태라 높게 나올까 봐..)
Attention: 0.5993206298011964
도대체 값이 어디까지가 최대인거지? 집중 한번 해볼까? 하다가 한곳에 집중하지 코드를 훑어보고 있었을 때
Attention: 0.7456045268742625
어라? 왜 낮은 거지.. 하고 함수 안을 살펴보고 있었을 때 (함수 들어갈 때 화면이 바뀌면서 집중력 더 떨어짐)
Attention: 0.45490847948134255
그냥 한곳에 집중해 보자 하고 한 함수만 가까이서 집중하며 보고 있었을 때
Attention: 1.2981097661167502
측정하면서 어떤 상황인지 함께 적어봤다..
확실히 그 상황마다의 집중도를 확실하게 캐치하는 것 같다. 정규화는 되어있지 않아서 확인하기는 좀 힘들긴 하지만..
저게 0 ~ 1의 값이 아닌 이유는 뭐 당연하지만 값의 범위가 달라서이다.. 저거를 0 ~ 1로 맞추는 방법이 있긴 하겠지만.. 뭐 있겠지만 생각한다. 참고로 뭐 max 값 min 값 해서 범위 찾아서 그걸로 0 ~ 1로 맞추는 걸 생각해 보긴 했는데 어차피 측정할 때 데이터를 이상하게 하는 방법도 있고 개인마다 다 차이 나서 맞추기가 어려울 것 같긴 하다. 뭐 찾아보면 어딘가에는 0 ~ 1로 맞추는 게 있긴 하겠다만.. 어차피 다음 글에서 인공지능으로 하는 게 0 ~ 1 값이다.
추가로 이전에 말했던 것 같은데 왼쪽은 근육이 발달하지 않은 건지 잘 안되지만 오른쪽은 뭔가 귀를 위로 올린다 생각하며 힘준 상태로 이를 물어버리면 오른쪽 귀 쪽이 뭔가 위로 올라가며 힘을 주는 듯한 느낌이 난다.
이 상태로 측정해 버리면 베타 값인가? 그게 파워가 확 높아져버림..
그렇게 되면 집중도를 조작할 수 있다. 심각하게..
그 상태로 측정하게 되면 이렇게 나온다..
Attention: 4.007621255928729
저거 힘주는 건 기숙사 방에서 해보다가 어쩌다가 집중하려고 힘줬더니만 진짜 돼버려서 알게 된 것..
참고로 기기를 벗은 상태로 측정하면 -1000 같은 결측값과 이상한 값들 때문에 이렇게 나온다.
Attention: 19.663765197669104
암튼 이상하게 나온다. 이래서 0 ~ 1 값으로 맞추기는 좀 어려울 것 같긴 하다.. 뭐 극단적으로 지금 생각나는 방법으로는 범위를 -1000 ~ 1000으로 해서 하면 될 것 같긴 한데, 이러면 집중을 해도 값이 작게 나올 테니 패스
그리고 추가로 실시간으로 측정하는 걸 원한다면.. 아래 코드로 해보는 걸 추천한다.
from time import sleep
import keyboard
from brainflow.board_shim import BoardShim, BrainFlowInputParams, BoardIds
from brainflow.data_filter import DataFilter
board_id = BoardIds.MUSE_2_BOARD
params = BrainFlowInputParams()
params.serial_number = "Muse-0465" # Muse 2의 고유 시리얼 넘버
board_shim = BoardShim(board_id, params)
use_data_seconds = 5 # n초 동안 데이터 수집
sampling_rate = BoardShim.get_sampling_rate(board_id)
eeg_channels = BoardShim.get_eeg_channels(board_id)
num_points = use_data_seconds * sampling_rate # 몇 초 동안의 데이터를 가져올지
# Muse 2 연결
board_shim.prepare_session()
# Muse 2 데이터 수집 시작
board_shim.start_stream()
# n초 + 1초 동안 데이터 수집 - 안하면 오류남
sleep(use_data_seconds + 1)
while True:
# 나가기 조건
if keyboard.is_pressed('q'):
break
# 수집한 데이터를 변수에 저장
data = board_shim.get_current_board_data(num_points)
# 예측에 필요한 데이터 추출
bands = DataFilter.get_avg_band_powers(data, eeg_channels, sampling_rate, True)
feature_vector = bands[0]
# 집중도 예측
print(f"Attention: {feature_vector[3] / feature_vector[2]}") # Beta / Alpha
# Muse 2 데이터 수집 정지
board_shim.stop_stream()
# Muse 2 연결 해제
board_shim.release_session()
실행하려면 pip install keyboard로 keyboard 라이브러리 설치하고 실행할 수 있다.
간단하게 설명하면 처음에 데이터 수집을 위해 수집 초 + 1초를 기다린 후
while로 반복하면서 반복될 때마다 최근의 5 * 256 데이터를 가져오고 그걸로 집중도를 계산해서 바로 출력하는 코드이다. 그리고 키보드로 q를 누르면 종료된다.
이 코드의 함정이라면 집중을 한 것을 보고 싶다면 집중한 후에 바로 보는 것은 하기 힘들고 집중하고 설정한 초가 지난 후에 봐야 집중도를 잴 수 있다는 점이다. (ㅋㅋ)
뭐 저 초를 1초로 바꿔도 되기는 하지만.. 정확도는 낮아지니 추천은 안 하지만.. 수업 자료(PPT)에서는 1초로 했었기 때문에.. 해봐도 문제 될 건 아마 없지 않을까.. 하는..
암튼 이걸로 Beta / Alpha 수식으로 집중도를 계산해 보는 건 여기에서 끝!
이거 새벽 2시에 작성하기 시작했는데.. 벌써 8시네.. 허허.. 심지어 더 길어 보이네..
아래 코드는 Brainflow로 Muse 2를 연결하고 1초간 데이터를 수집하는 코드이다.
import pandas as pd
from time import sleep
from brainflow.board_shim import BoardShim, BrainFlowInputParams, BoardIds
board_id = BoardIds.MUSE_2_BOARD
params = BrainFlowInputParams()
params.serial_number = "Muse-0465" # Muse 2의 고유 시리얼 넘버
board_shim = BoardShim(board_id, params)
use_data_seconds = 1 # 1초 동안 데이터 수집
sampling_rate = BoardShim.get_sampling_rate(board_id)
num_points = use_data_seconds * sampling_rate # 몇 초 동안 몇개의 데이터를 가져올지
# Muse 2 연결
board_shim.prepare_session()
# Muse 2 데이터 수집 시작
board_shim.start_stream()
# 2초 동안 데이터 수집
sleep(use_data_seconds + 1)
# 수집한 데이터를 변수에 저장
data = board_shim.get_current_board_data(num_points)
# 저장된 데이터를 알기 위한 출력 코드
print(board_shim.get_board_descr(board_id))
# CSV로 저장
df = pd.DataFrame(data).T
df.to_csv(f"data.csv", index=False)
# Muse 2 데이터 수집 정지
board_shim.stop_stream()
# Muse 2 연결 해제
board_shim.release_session()
참고로 당시에 Brainflow나 Muse 2에 대한 정보들이 엄청 적어서.. 코드를 작성하는데 조금 어려움은 있었다..
그래도 현재 올린 코드는 내가 몇번이고 찾아보면서 그나마 다듬어서 제일 쉬운 데이터 수집 코드를 만들었다.
솔직히 변수 명은 딱히 생각 안나서.. 그냥 이해하기 쉬운 걸로 쓴 거다..
Muse 2 시리얼 코드 연결
암튼 코드를 설명하기 전에 Muse 2를 연결할 때는 시리얼 코드가 필요하여 그것부터 설명해 보면..
일단 Brainflow에서 Muse 2 기기를 인식하는 방식이 블루투스 연결 장치가 주변 블루투스 기기를 찾고 블루투스 이름으로 Muse 2 기기를 연결하게 되는 방식이다.
그런데 나의 경우 Muse 2 기기가 주변에 여러 개 있는 경우 특정 하나만 연결되도록 해야 했었다. 왜냐하면 나중에 수업 때 사용하거나 2개 이상 연결해서 프로젝트를 진행했어야 했기 때문에;;
그렇기에 특정할 수 있는 방법은 시리얼 넘버를 사용하는 것이다.
혹시라도 전체 시리얼 넘버가 공개되면 문제가 있을 수 있어서 가리고 올렸다.
하나는 머리에 착용했을 때 왼쪽 귀에 해당하는 곳에 적힌 시리얼 넘버와 박스 상자 위에 적힌 시리얼 넘버이다.
기기에서는 상단에 있는 MUSE-0465를 확인하면 되고 박스에서는 S/N : ____-____-0465를 확인하면 된다.. 그냥 숫자 4자리 확인하면 된다.
암튼 저 4자리 숫자가 기기를 특정할 수 있도록 하는 것인데.. 저것만 알아두면 된다..!
암튼 이제부턴 코드 설명!
코드 설명
import pandas as pd
from time import sleep
from brainflow.board_shim import BoardShim, BrainFlowInputParams, BoardIds
먼저 필요한 라이브러리를 불러온다..!
여기에서 sleep 함수는 몇 초 동안 데이터를 수집하는지에서 대기하도록 하려고 쓰는 것이고.. pandas는 데이터를 저장하기 위한 것, 나머지는 Brainflow 라이브러리들이다.
참고로 pandas는 같이 설치가 안되기 때문에 pip install pandas로 설치하면 된다.
board_id = BoardIds.MUSE_2_BOARD
params = BrainFlowInputParams()
params.serial_number = "Muse-0465" # Muse 2의 고유 시리얼 넘버
board_shim = BoardShim(board_id, params)
여기가 가장 중요하다고 생각되는 부분이다.
Muse 2의 기기를 선택시키고 시리얼 넘버를 정하는 부분이다.
먼저 board_id이다. board_id는 BoardIds라는 클래스에서 특정 기기의 정보들을 작성하여 연결을 돕거나 하는 그런 클래스라고 생각하면 되는데.. 미리 어떤 기기를 연결할지 선택을 해야 한다.
위에 참고 사항으로 올려둔 링크를 타고 가보면 Muse 2가 2개일 것이다.. (참고로 Muse S나 Muse 2016도 있는데 그건 다른 기기;;)
MUSE_2_BLED_BOARD = 22 #:
MUSE_2_BOARD = 38 #:
왜 2개이냐 하면.. 이전 글에서 말했던 BLED112 동글 때문이다.
MUSE_2_BLED_BOARD는 BLED112 동글로 연결할 때 필요한 번호이다. 이젠 딱히 쓰이지는 않겠지만.. 만약 동글로 연결하게 된다면 저걸 선택하면 된다..
하지만 나는 일반 블루투스 연결 장치로 연결할 것이기 때문에 MUSE_2_BOARD로 선택한 것이다..!
BrainFlowInputParams는 EEG 기기의 추가 정보들을 지정해서 연결할 수 있도록 해주는 클래스이다.
여기에서는 시리얼 넘버만 사용해서 연결하지만 다른 EEG 기기들을 위해 IP나 Mac Address 등 다른 지정 방법들도 있다.
아무튼 저 클래스를 받아서 시리얼 넘버를 지정하게 되는데..
위에서 말했듯이 나의 경우 Muse-0465가 시리얼 번호이기 때문에 Muse-0465 시리얼 번호를 사용하면 된다.
그렇기 때문에 꼭 자신의 시리얼 번호를 확인 후 작성해서 연결하면 될 것 같다..
그리고 그냥 기기를 한 개만 사용하거나 굳이 시리얼 넘버를 지정하지 않아도 되는 경우라면 그냥 저 serial_number를 설정하는 부분은 주석 처리 하면 된다.
따로 지정하지 않으면 그냥 블루투스 장치 검색할 때 처음으로 뜨는 Muse 2 기기를 연결하게 된다..
use_data_seconds = 1 # 1초 동안 데이터 수집
sampling_rate = BoardShim.get_sampling_rate(board_id)
num_points = use_data_seconds * sampling_rate # 몇 초 동안 몇개의 데이터를 가져올지
여기서는 몇 초간의 데이터를 가져올지 설정하는 부분이다.
나는 테스트로 간단하게 작동하는지만 보는 것이기 때문에 1초를 사용한다.
그리고 sampling_rate를 기기 정보에서 가져온다. 그냥 sampling_rate = 256으로 작성해도 되긴 한다.
어쨌든 기기들마다 차이가 있으므로 Brainflow에서 미리 정의한 sampling_rate 정보를 가져온 것..
참고로 더 많은 추가 정보들을 가져올 수도 있다.
그리고 num_points인데.. 이거는 나중에 몇 개의 데이터를 가져올지 사용할 때 쓴다.
나는 1초 동안의 데이터를 가져오고 이 기기의 초당 데이터 개수는 256이기 때문에 256개를 가져오도록 한다. 만약 2초라면 512개를 가져오도록 하면 된다. 마찬가지로 그냥 num_points = 256으로 작성해도 된다.
# Muse 2 연결
board_shim.prepare_session()
# Muse 2 데이터 수집 시작
board_shim.start_stream()
# 2초 동안 데이터 수집
sleep(use_data_seconds + 1)
# 수집한 데이터를 변수에 저장
data = board_shim.get_current_board_data(num_points)
이번엔 연결하고 데이터를 수집하고 데이터를 가져오는 부분이다.
주석에 적힌 대로 이해하면 된다.
연결하고 수집을 시작하도록 명령한다.
그 후 2초 동안 데이터를 수집한다. 이렇게 하는 이유는 아래에서도 얘기할 텐데 Muse 2 기기는 256hz라고 해도 연구용으로 나온 기기는 아니다 보니.. 초당 256개의 데이터가 정확히 가져와지지는 않는 것 같다.
그렇기 때문에 2초를 수집해서 1초를 수집해서 조금 부족한걸 나머지 1초에서 가져오도록 하기 위해서 저렇게 한 것이다.
뭐 나는 간단하게 하려고 저렇게 했지만 초마다 정확하게 데이터를 가져와야 한다면 초를 판단해서 데이터가 256개가 아니라도 가져오도록 해야 할 것이다.. 하지만 귀찮고 어렵기 때문에 여기에서는 패스..
그 후 board_shim의 get_current_board_data로 이전에 지정한 가져올 데이터 개수대로 데이터를 가져온다.
즉 2초간 측정한 데이터에서 1초 분량인 256개의 데이터를 가져온다는 것이다.
참고로 get_current_board_data는 이름에서 짐작할 수 있듯이 최근의 특정 개수의 데이터를 가져온다는 것이다.
만약 지금까지 측정한 전체 데이터를 가져오도록 할 것이라면 get_board_data를 사용하면 된다.
# 저장된 데이터를 알기 위한 출력 코드
print(board_shim.get_board_descr(board_id))
# CSV로 저장
df = pd.DataFrame(data).T
df.to_csv(f"data.csv", index=False)
# Muse 2 데이터 수집 정지
board_shim.stop_stream()
# Muse 2 연결 해제
board_shim.release_session()
이번 건 데이터를 csv로 저장하고 데이터 수집 종료 후 Muse 2 기기의 연결을 해제시킨다.
먼저 print(board_shim.get_board_descr(board_id)) 이 코드는 csv로 저장하는 것을 설명한 뒤 설명할 것이다. (쓰고 있을 때 생각해 보니.. 그냥 csv 아래에 적어도 되긴 할 텐데라고 생각하긴 했는데.. 귀찮다..
먼저 csv로 저장하는 것을 보면
그냥 알 수 있듯이 데이터를 DataFrame에 등록시키고 data.csv로 저장하는 것이다.
DataFrame에 등록할 때 T는 그냥 행열 바꾸는 것이다. 저거 안 하면 csv로 열었을 때 읽기 좀 불편하다..
그리고 index를 없애는 건 굳이 필요 없어서.. 더 복잡하게 보일 것 같으니..
그리고 데이터 수집을 종료하고 연결을 해제시키는데 만약에 연결 해제 코드를 안 쓰고 실행해 버려서 코드가 끝나면 Muse 2 기기는 연결된 상태로 코드가 끝나게 될 수 있다.. 이럴 경우 다시 연결할 때 이미 컴퓨터에 연결되어 있기 때문에 다시 연결이 안 된다. 그래서 다시 연결하려면 Muse 2 기기의 전원 버튼을 꾹 눌러서 전원을 강제 종료 시키고 다시 켜서 연결시키도록 해야 한다. 귀찮게 다시 연결하도록 할 것이 아니라면 종료 코드는 써주는 게 좋다.
참고로 이미 연결이 잘 되어있는지 확인하려면 Muse 2의 LED 인디케이터를 확인하면 된다. 연결이 되어있을 땐 전체에 불이 들어와 있고 연결이 아직 안 되었을 땐 왔다 갔다 led가 빛난다.
암튼 이제 print(board_shim.get_board_descr(board_id)) 에 대해서 설명할 텐데 이건 수집한 데이터의 칼럼 이름이다.
출력된 것에서 숫자들은 칼럼이다. 'eeg_channels': [1, 2, 3, 4]는 1, 2, 3, 4 컬럼이 eeg 채널이라는 것을 의미한다.
그러면 저기에서 설명한 것을 토대로 csv를 수정해 보면!
package_num_channel
TP9
AF7
AF8
TP10
other_channels
timestamp_channel
marker_channel
16
-1000
-987.3046875
-945.8007813
709.4726563
0
1739688027.40830
0
16
-910.6445313
-856.9335938
-998.5351563
-795.8984375
0
1739688027.41217
0
16
-623.046875
-791.9921875
-981.9335938
-1000
0
1739688027.41605
0
16
-866.2109375
-925.2929688
-933.59375
202.6367188
0
1739688027.41992
0
17
-1000
-1000
-892.578125
999.5117188
0
1739688027.42472
0
17
-780.2734375
-899.4140625
-963.3789063
-389.6484375
0
1739688027.42953
0
17
-482.421875
-773.4375
-1000
-1000
0
1739688027.43433
0
17
-552.734375
-866.2109375
-917.96875
-216.3085938
0
1739688027.43913
0
17
-760.2539063
-991.6992188
-841.796875
999.5117188
0
1739688027.44394
0
17
-636.2304688
-936.5234375
-862.3046875
242.1875
0
1739688027.44874
0
17
321.2890625
-769.0429688
-763.671875
-1000
0
1739688027.45354
0
17
-59.5703125
-805.6640625
-835.4492188
-407.7148438
0
1739688027.45835
0
17
-1000
-979.9804688
-931.1523438
999.5117188
0
1739688027.46315
0
17
-635.2539063
-963.8671875
-836.9140625
511.71875
0
1739688027.46795
0
17
-486.8164063
-818.8476563
-887.2070313
-1000
0
1739688027.47275
0
17
-990.7226563
-813.4765625
-1000
-891.1132813
0
1739688027.47756
0
18
-979.9804688
-954.1015625
-948.7304688
675.78125
0
1739688027.48136
0
18
-724.1210938
-985.3515625
-816.40625
956.5429688
0
1739688027.48517
0
18
-869.140625
-876.4648438
-904.296875
-541.9921875
0
1739688027.48897
0
이렇게 할 수 있다!
표 맞추기가.. 컴퓨터로 보면 그나마 보이기는 하는데.. 모바일에서는 잘 안 보일 수 있으니.. 웬만하면 데스크톱으로 보는 것을 추천!
아무튼 이제 표를 보면 대충 이해가 될 것이다. 참고로 'eeg_channels': [1, 2, 3, 4], 'eeg_names': 'TP9, AF7, AF8, TP10' 이것이 1, 2, 3, 4로 정의되어 있지만 각각은 eeg_names도 의미하기 때문에 저걸로 대입한 것이다.
이제 이름과 매칭해서 보면 이해하기 쉬울 것이다.
package_num_channel : 지금 보고 이해했는데.. 패킷 번호 같다. 데이터 받아올 때 번호 같은 거?
TP9, AF7, AF8, TP10 : 전극에서 측정된 데이터.. (뇌파)
other_channels : 잘은 모르겠지만.. 다른 기기에서 쓰일지도..
timestamp_channel : 유닉스 시간으로 몇 초에 측정된 데이터인지
marker_channel : 이것도 잘은 모르겠다. 다른 기기에서 쓰일지도..
아무튼 내가 이해한 걸로 써보면 대충 이렇다. package_num_channel은 당시에는 딱히 필요 없는 것 같아서 뭔지 신경 쓰진 않았는데.. 패킷 번호인 것 같다.
아무튼 지금은 봐서도 뭐가 뭐인지 모르겠다.
나중에 이걸로 처리를 해보면 알 수 있게 되겠지만.. 일단 이렇다.
참고로 데이터에서 -1000으로 보이는 건 결측값이다. 즉 측정이 되지 않거나 이상하게 된 것..
왜냐하면 내가 빠르게 실행하려고 머리에 착용하지 않고 실행해서 측정한 것이기 때문..
그러면 한번 측정된 것을 그래프로 봐보자!!
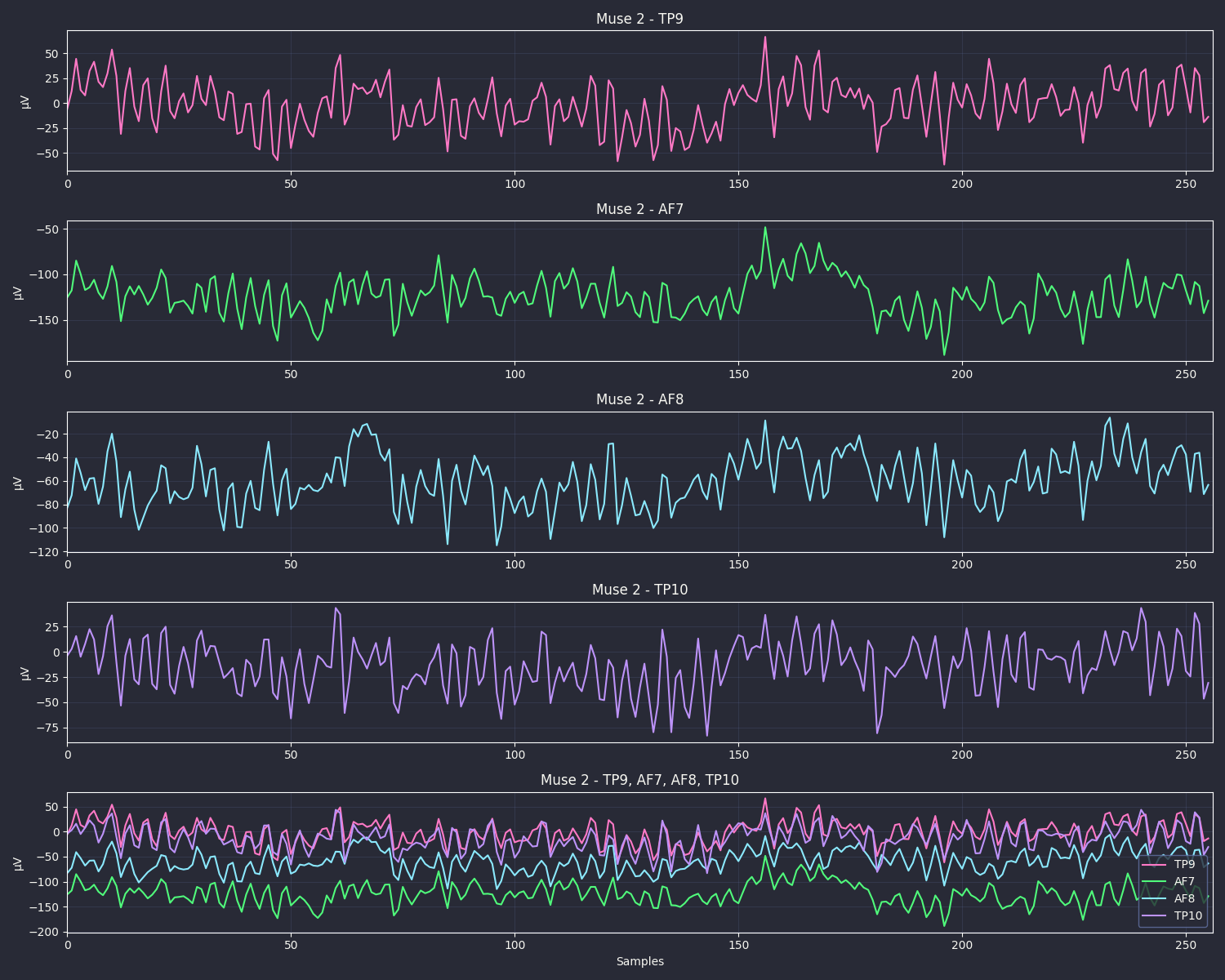
그래프로 보기
이것이 그래프로 표현했을 때 이다!
색은 흰 배경에 할라 했는데.. 잘 안 보여서 내가 제일 좋아하는 드라큘라 테마로 설정했다.
참고로 이건 위에 예시로 올린 데이터는 아니다. 새로 측정한 것이기 때문에..
아무튼 저걸 보면 그래프가 들쑥날쑥하다.. 이유는 당연하게도 아까 말했던 것처럼 착용하지 않고 측정해서 그렇다.
그러면 한번 직접 써서 측정해 보겠다!
쓰는 방법은.. 전극은 이마 쪽으로 하고 귀에 거는 형태로 쓰면 된다.
어딘가 쇼핑몰에 있던 사진
위 사진처럼 써서 측정하면 된다.
쓸 때 팁은 최대한 길게 뽑은 뒤에 귀에 걸고 앞부분을 이마에 최대한 밀착하게 누르면서 다시 길게 뽑은 걸 줄이면 된다.
참고로 이마를 까고 해야 해서.. 좀 쓴 모습을 들키기는 싫다;;
아무튼 착용하고 측정해 보았다!
이제 이것을 보면 알 수 있다! 이제 결측값이 없기 때문에 제대로 데이터가 어떻게 분포하고 있는지 알 수 있다!
아무튼 데이터가 이런 식으로 보이고 한다!
그래프 그리는 건 귀찮기 때문에 ChatGPT 한테 부탁했다! 그렇기에 그래프 그리는 코드는 딱히 공유 안 하겠다!
암튼 각각의 뇌 부위가 어떤 값인지 알 수가 있는데.. 각각이 다르게 측정된다는 게 신기하긴 하다..
이것을 이용해서 이후에는 델타 베타 알파 이런 값으로 바꾸고 집중도나 이런 것도 측정해 보면 더 신기해진다!!
암튼 이로써 코드를 작성해서 Brainflow랑 Muse 2를 연결해 보고 데이터 저장은 끝났다!
거의 5시간 이상 째 쓰고 있는데.. 하아 역시 힘들긴 하다.. 그래도 글 연습 하는 겸 쓰는 것이기도 하니 재밌을지도..?
그리고 아래는 위에 코드 설명에서 왜 1초를 더 추가 측정하는지에 대한 것이다.
데이터를 1초 더 측정하는 이유
위에서 말했던 2초를 측정하는 이유와 이전 글의 Muse 2에 대한 정보를 말할 때도 한번 말했던 것이다.
Muse 2의 기기 정보를 보면 초당 256개의 데이터가 측정된다고 작성이 되어있는데..
실제로 측정을 해보면 초당 256개가 모이지 않는 것을 발견할 수 있다.. 아닐 수도 있지만;;
아무튼 이런 이유를 생각해 보면 블루투스로 연결하다 보니 발생하는 것 같다.
관련 글은 Muse 2016에 대한 얘기지만 Muse 2와도 관련이 있는 것 같기 때문에 같이 첨부!
아래 사이트에 적힌 말처럼 블루투스로 데이터를 보내면서 손실들이 발생하는 것이 아닐까 생각된다..
추가로 이건 이 글과는 상관없지만.. C++에서 빌드할 때 한국어나 일본어등 유니코드를 사용하는 윈도우 컴퓨터에서 빌드할 시 생기는 오류를 해결하기 위한 간단한 코드 한 줄 추가한 커밋이다.. 당시 올릴 때 이게 맞나? 올려도 되나? 여러 검증을 하면서 떨리기는 했었는데.. 올리고 나니.. 굉장히 뿌듯했다..!!
이거 작성한 2일 후에 생각나서 추가로 작성하는 거지만..
Muse 2는 이렇게 생겼다.
참고로 저거 길이 조정 가능한데 저건 내가 착용할 때 맞춰놓은 길이이고.. (좀 더 길게 할 수 있다.)
길이를 제일 줄이면 이 정도.. (포장은 저 줄여진 상태로 온다.)
다이소에서 산 책상 패드.. 다한증인 나에겐 최고의 패드.. 참고로 키보드는 큰맘 먹고 지른 AK74
저 글을 살펴보면 BLED112라는 동글이 추가적으로 필요하다고 나와있다.. 이 동글을 컴퓨터에 꽃아서 Muse 2랑 Brainflow랑 연결할 수 있었는데.. 처음에 Muse 2를 검색하면서 저 글을 보았을 때.. 진짜 동글이 필요한가라고 생각했었다.. 그런데 2차 회의가 며칠 안 남아서 동글을 살 시간도 없고.. 구매하기도 어려웠어서.. 조금만 더 찾아봤었다.. 당시에는 C++를 먼저 사용해서 연결해 보려고 했기 때문에 BLE 옵션이 있다는 것도 이후에 알았었다..
대학교에 입학하고 2주 째에 어느 교수님께서.. 나에게 학생 연구원에 들어올 생각이 없는지 물었었다.
그러고 5월 부터 학생 연구원을 시작했는데, 당시에 EEG를 사용한 연구 때문에 EEG 기기를 찾아봐야 했었다.
그때 나는 Muse 2도 찾아보기는 했었지만.. 개발자 용으로 사용되기 보다는 일반적인 용도로 사용되는 경우가 많고 약간의 문제점이 검색됬었어서.. Muse 2 기기는 선정을 안했었다.. 그런데 나중에 회의에서 찾아본 EEG 기기에 대해서 말했는데.. Muse 2 기기는 자세하게는 말하지 않았지만.. 이미 교수님은 회의 전에 Muse 2 기기를 배송하셨던 것 같다.. 그래도 EEG 기기에 대해서 알게되었으니 다행이었지만..
솔직히 가격도 싸고 배송도 쉽긴 하다..
암튼 연구원에서 Muse 2를 사용해보는 것에 대해 해봤던 대부분을 써볼려고 한다..!
(그리고 지금 이 글을 쓰는 시점이 2025년 2월 16일인데.. 다시 교수님께 이 기기를 돌려줘야 해서.. 2025년 2월 28일이 되기 전에는 빨리 작성해야한다.. 뭐.. 못 쓰면.. 그냥 내가 따로 저장해둔 정보로 쓰거나.. 그만쓰게 될지도 모른다..)
(대부분의 글은 전부 나 혼자서.. 찾은 정보나 방법들이다.. EEG 쪽은 거의 내가 담당했기 때문에..)
EEG
EEG(Electroencephalography, 뇌전도)는 전극을 통해 뇌의 전기적 활동을 기록하는 전기생리학적 측정 방법이라고 위키백과에 나와있는데..
그냥 내가 이해한걸로는 머리에 전극을 부착시켜 신호를 측정하는 것으로 알고 있다. 그냥 머리에 장치를 부착시켜서 뇌의 전기적 신호를 읽는다 생각하면 될 것 같다..
게임용으로 지원하는 SDK이고 이 SDK를 사용해서 아이트래킹이 지원되는 게임을 만드는 것 같다.
그래서 이걸 쓰기위해 보니 메일을 보내서 요청하라고 적혀있다.. 그래서 보냈더니..
한국어로 답변이 왔는데.. 아이트래커에 해킹을 시도하거나 다르게 이용을 하는 경우가 있어서 SDK를 못 준다는 말만 왔었다.. 개인적으로 사용할 것이라고 얘기해도 불가능이라고 했다.
그래서 그냥 포기할까 하고 한가지 생각이 들었다. 이 회사는 유명하니깐 누군가가 Github에 올려놓지 않았을까 하고..
그래서 찾아보니 진짜로 있었다. 32비트, 64비트 모두 Github에 아이트래커 프로젝트를 올리면서 같이 올려진 것들이 있다.
그래서 나는 이걸 다운받아서 시도했더니 아이트래커에 접근이 됬었던 것!
(근데 한가지 슬픈건.. 이 SDK가 C++과 C#만 가능한데.. 연구원에서.. 교수님과 나만 C++이 가능했던 것.. 그래서 이 연구와 관련된 프로그램을 제작하는건 모두 내가 맡아서 했었다.. 파이썬으로 실행할 수 있는 것이 github에 있던데.. 더 별로여 보여서 그냥 C++로 하기로 했다..)
일단 Stream Engine을 살펴보니 잘은 모르겠지만 내가 보고 있는 시선의 위치만 가져올 수 있는 것 같다. 뭐.. 게임 용이라 그런 것 같은데.. 아니면 내가 제대로 안 찾아본 것일 수도 있고..
아무튼 내가 보고 있는 위치만 가져올 수 있으니깐.. 사용할 수 있는 OSC는 "/tracking/eye/CenterPitchYaw" 이거다. 이거는 문서에 잘 설명 되어있다.
그리고 눈을 감았는지에 대한건 "/tracking/eye/EyesClosedAmount" 이걸 사용하면 될 것 같다.
아무튼 이걸 알았으니 이제 예제 코드를 실행해볼껀데, 그냥 실행하면 이런 오류가 난다. 아마도 내꺼가 Github에서 가져와서 버전이 낮은 것 때문에 그런 것 같은데..
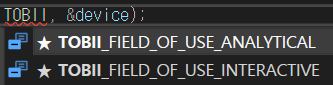
// Connect to the first tracker found
tobii_device_t* device = NULL;
result = tobii_device_create(api, url, TOBII_FIELD_OF_USE_STORE_OR_TRANSFER_FALSE, &device);
assert(result == TOBII_ERROR_NO_ERROR);
여기 코드에서 TOBII_FIELD_OF_USE_STORE_OR_TRANSFER_FALSE 이게 오류가 난다.
그냥 해결 방법은 그냥 저거 빼고
사진에 나온거 2개 중에 아무거나 넣으면 된다.
그리고
이런 오류 나면.. 뭐 다르게 해결하는 방법이 있지만 빠르게 테스트 하기 위해 맨 상단에 이걸 넣는다.
#define _CRT_SECURE_NO_WARNINGS
아무튼 이러면 오류가 사라진다.
이제 실행해보면 Tobii Eye Tracker이 정상적으로 연결 되어있는 경우 작동하는데 해보면 내가 보고 있는 시선이 x, y로 나올꺼다. 그런데 내가 눈을 감거나 감지할 수 없는 영역을 쳐다보면 아무것도 출력이 안되는데.. 이걸 알 수 있다는 것은 눈을 깜박이는 것을 알 수 있다는 것이다! 확실히 알기 위해 코드를 수정했다!
void gaze_point_callback(tobii_gaze_point_t const* gaze_point, void* /* user_data */)
{
// Check that the data is valid before using it
if (gaze_point->validity == TOBII_VALIDITY_VALID)
printf("Gaze point: %f, %f\n",
gaze_point->position_xy[0],
gaze_point->position_xy[1]);
else // 추가
printf("Gaze Error\n"); // 추가
}
// 추가 라고 되어있는 것이 내가 추가한건데 그냥 인식 안되면 출력하라는거다..
이렇게 하면 정상적으로 눈을 깜으면 Gaze Error이 표시되고 감지 영역에서 눈을 움직이면 쳐다보는 곳이 잘 출력된다..!
일단 위에 명령어 처럼 친다. 명령어는 원하는 폴더에서 치면 되는데 나는 그냥 Downloads 폴더에서 했다.
이렇게 하면 brainflow 깃허브 파일이 모두 다운로드 되고 cmake 라이브러리를 설치하고 brainflow의 tools 폴더로 이동해서 build.py의 도움 내용을 출력하는 것이다.
usage: build.py [-h] [--oymotion] [--no-oymotion] [--msvc-runtime {static,dynamic}] [--generator GENERATOR]
[--arch {x64,Win32,ARM,ARM64}] [--cmake-system-version CMAKE_SYSTEM_VERSION] [--build-dir BUILD_DIR]
[--brainflow-version BRAINFLOW_VERSION] [--cmake-install-prefix CMAKE_INSTALL_PREFIX] [--use-openmp]
[--onnx] [--warnings-as-errors] [--debug] [--clear-build-dir] [--num-jobs NUM_JOBS] [--bluetooth]
[--no-bluetooth] [--ble] [--no-ble] [--tests] [--no-tests]
options:
-h, --help show this help message and exit
--oymotion
--no-oymotion
--msvc-runtime {static,dynamic}
how to link MSVC runtime
--generator GENERATOR
generator for CMake
--arch {x64,Win32,ARM,ARM64}
arch for CMake
--cmake-system-version CMAKE_SYSTEM_VERSION
system version for win
--build-dir BUILD_DIR
build folder
--brainflow-version BRAINFLOW_VERSION
BrainFlow Version
--cmake-install-prefix CMAKE_INSTALL_PREFIX
installation folder, full path
--use-openmp
--onnx
--warnings-as-errors
--debug
--clear-build-dir
--num-jobs NUM_JOBS num jobs to run in parallel
--bluetooth
--no-bluetooth
--ble
--no-ble
--tests
--no-tests
일단 이게 내용인데 일단 내가 아는 것 중에 먼저 말하자면 나중에 C++에서 사용할 때 Release로 빌드 해야하는 것 같다.. 만약에 Debug로 빌드를 하고 싶으면 --debug를 추가해야하는 것 같다. 근데 또 저거 추가하면 Release가 안먹힌다...
그리고 기본적으로 --bluetooth는 켜져있다. (bluetooth는 일반 블루투스 장치를 지원하는 것 ble와는 다른 것)
그리고 --ble가 필요한건데 저전력 블루투스를 지원하게 하는 것이다. 그렇기 때문에 명령어는 아래 처럼 치면 된다.
python build.py --ble
그런데 위에 소제목에서 말한 것 처럼 나는 이게 이상하게도 안된다.. (더 신기한건 --ble를 제거하면 되긴 한다)
실행하면 아래처럼 오류가 뜬다. (글 쓰면서 실행하는데.. 역시 C++ 빌드는 너무 오래걸리는..)
Brainflow.vcxproj -> C:\Users\pkdpm\Downloads\brainflow\build\Release\Brainflow.lib
Traceback (most recent call last):
File "C:\Users\pkdpm\Downloads\brainflow\tools\build.py", line 306, in <module>
main()
File "C:\Users\pkdpm\Downloads\brainflow\tools\build.py", line 302, in main
build(args)
File "C:\Users\pkdpm\Downloads\brainflow\tools\build.py", line 287, in build
run_command(cmd_build, cwd=args.build_dir)
File "C:\Users\pkdpm\Downloads\brainflow\tools\build.py", line 22, in run_command
raise ValueError('Process finished with error code %d' % p.returncode)
ValueError: Process finished with error code 1
이런 오류가 뜨게 된다.. 아무리 해도 지우고 다시 해보고 다른 것도 켜보고 하는데도 안되었다.. (이것 때메 1시간을 날린..)
그래서 결국 안되서 그냥 수동으로 빌드하기로 했다..
2024-09-15 변경 - 해결 방법
지금 이건 9월 15일인 오늘 추가로 작성하는 것이다.
나는 이 문제가 다시 무엇인지 볼려고 확인을 해보니.. 문제를 알아냈다.
간단하게 말한다면 컴파일을 하는데 UTF-8로 컴파일이 되지 않고 다른 인코더로 컴파일이 되면서 오류가 발생한 것 같다.
이 문제를 해결하는 제일 간단한 방법은 윈도우 검색 창에 "국가 또는 지역"을 검색하고 창을 열어서 관리자 옵션에 들어가면
이런식으로 "시스템 로캘 변경"이라고 뜬다. 저걸 눌른 후
아래 보이는 "Beta: 세계 언어 지원을 위해 Unicode UTF-8 사용"를 활성화 한다.
이렇게 한 후에 다시시작하고 컴파일을 하면 정상적으로 된다.
아마도 한국어 윈도우나 일본어 윈도우 이런건 아마도 EUC-KR EUC-JP 같은 인코더로 되어있어서 컴파일할 때 저걸로 컴파일 해서 오류 나는 것 같은데 이건 윈도우에서 기본으로 쓰는 인코더를 UTF-8로 바꿔서 해결할 수 있는 것 같다.
일단 나는 이 문제를 발견해서 빌드할 때 처음부터 UTF-8로 빌드되도록 소스코드를 수정해서 풀 리퀘스트를 했다.
그리고 컴파일 되면 "installed"라는 폴더가 생기는데 여기에 inc 폴더와 lib 폴더가 생긴다. 이거를 가져다가 이 글 아래에 설명되어있는 대로 하면 정상적으로 작동한다! (도데체 왜 저 문제를 이제야 찾은걸까..)
추가적으로 Muse에 대한 내용이 잘 못 기재되어있다.
구글에 검색해보면 Muse 기기의 EEG 이름이 TP9, AF7, AF8, TP10 로 되어있는데 여기에서는 TP9, Fp1, Fp2, TP10 이걸로 설정 되어있다. 그래서 결국에는 이 정보를 어디에서 가져오는지 찾아내고 정확한 정보를 기재해서 이것도 풀 리퀘스트를 했다. (심지어 Muse 관련 코드를 열어봐도 Fp1, Fp2는 없고 AF7, AF8만 있다.. 엄..) (처음으로 남의 프로젝트에 풀 리퀘스트를 해보았어서.. 심장이 엄청 뛰어댔었다.. 내가 수정해도 되는게 맞을까 하고..) https://github.com/brainflow-dev/brainflow/pull/744
일단 아쉽게도 나는 CMake를 예전에 OpenCV 빌드하다가 빡쳐서 포기했던 녀석이라.. 왠만하면 쓰기 싫었다.. (지금은 VCPKG 쓰는..)
그렇지만 일단 이건 연구 과제이기 때문에 해야했다.
마찬가지로 아까 위에 올린 링크에 같이 설치 방법이 있다. (저거 링크 들어가보면 In VS installer make sure you selected “Visual C++ ATL support” 저거를 VS 인스톨러에서 설치하라는건데 2022 버전에선 사라진 것 같다. 없기도 하고 설치 안해도 문제가 없는 것 같다.)
이렇게 뜨는데 여기에서 Where is the source code에는 Browse Source... 버튼을 눌러 brainflow 위치로 잡는다.
나 같은 경우는 다운로드 폴더에 brainflow를 넣었기 때문에 이걸로 지정했다.
C:\Users/pkdpm/Downloads/brainflow
그러면 그 후에는 Where to build the binaries 폴더를 선택하는건데 이건 빌드 폴더를 만드는거다.
Browse Build...을 눌러서 폴더를 지정한다. 하지만 이건 일단 위에 있는 경로로 설정을 하고 뒤에 build만 붙이면 된다.
이렇게
C:/Users/pkdpm/Downloads/brainflow/build
이렇게 하면 아래처럼 된다.
이제 여기에서 프로젝트를 만들어야 하는데
아래에 있는 Configure 버튼을 눌른다.
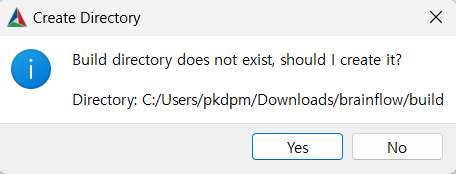
혹시 만약에 아래 사진 처럼 경고 같은거 뜨면 Yes 눌르면 된다. build 폴더 지정했으면서 build 폴더를 안만들었으니 만들어주겠다는 표시이다.
암튼 Configure 눌르게 되면 이렇게 뜨는데
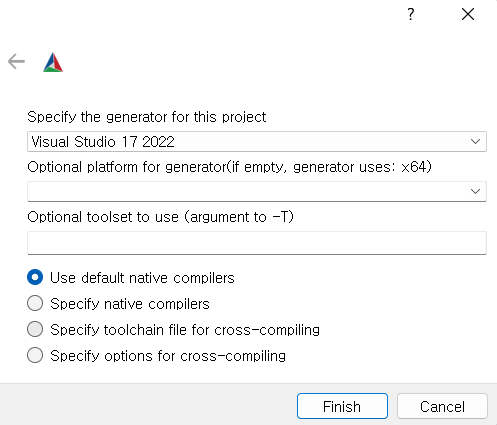
여기에서 맨 위에 있는 Visual Studio 17 2022는 그냥 자신이 설치한 Visual Studio 버전이다. BrainFlow에선 2019를 권장하고 2017만 말하고 있는데 테스트 해보니 2022도 상관없는 것 같다. 그냥 바로 Finish 눌른다.
그런 후에는 아무것도 없던 곳에 이런 화면처럼 바뀐다.
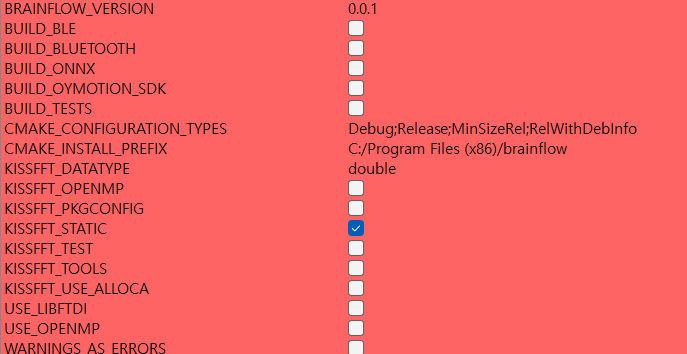
이제 여기에서 어떤걸 빌드할지 선택할 수 있는데 여기에서 Muse 2나 Muse S가 지원될 수 있는 BUILD_BLE를 선택한다.
그리고 여기에서 좀 고생한건데.. 나중에 컴파일 하다 보면 이상하게 INSTALL 프로젝트를 빌드하면 setlocal 이러면서 오류가 뜬다.. 대충 나한테 권한 없는 곳에 폴더 두라 했다면서 화내는 오류인 것 같다.
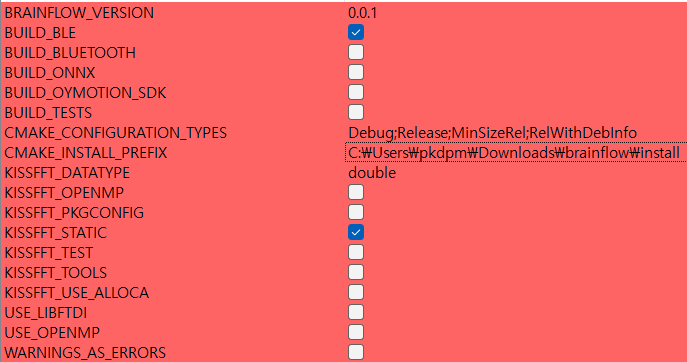
그렇기 때문에 미리 방지하기 위해 CMAKE_INSTALL_PREFIX 부분을 수정한다. 저게 이제 INSTALL 프로젝트를 빌드하면 빌드된걸 모으는건데 어디로 모을껀지인거다.
폴더 위치는 아무데나 잡아도 되는데 관리자 권한 필요없는 폴더로 지정한다. 나는 그냥 brainflow 안에 install 폴더 안에 넣기로 했다.
내가 말한거 키면 이렇게 아래처럼 된다.
이제 아래쪽에 Generate 버튼 눌르면 바로 프로젝트가 만들어지게 된다.
다 만들어지고 나면 아래 사진처럼 원래는 Open Project 버튼이 비활성화였는데 활성화로 바뀌게 된다.
그러면 빌드 하기위해 바로 Open Project를 눌른다!
빌드하기
Open Project를 눌르면 바로 Visual Studio가 켜지는데 만약에 안켜지만 직접 build 폴더 가서 키는걸로..
암튼 킨 후에 위에 보면
이렇게 생긴게 있다. 어떤걸로 빌드할지인데 아까전에 CMake 설정할 때 Debug는 따로 설정안했기 때문에 Release로 바꾼다. 그냥 눌러서 Release로 바꾸면 된다.
이렇게
그 후에는 이제 빌드를 해야하는데 ALL_BUILD를 눌러서 전부 빌드하면 좋겠지만 이상하게도 아까 추가했던 BLE에 대한건 ALL_BUILD에 추가가 안되어있는 것 같다. (BLE 프로젝트 빌드 안하고 하면 뭐 없다면서 오류남)
그래서 먼저 BLE 프로젝트 부터 빌드 해야하는데 그냥 simpleble 프로젝트를 오른쪽 클릭해서 빌드 버튼 눌르면 된다.
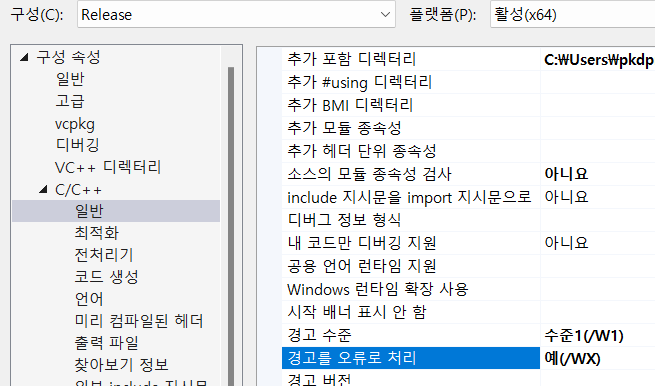
조금 시간이 걸리긴 하는데.. 하다보면 뜰 수도 있고 안뜰 수도 있는데 나 처럼 오류가 생길 수 있다.
오류 C2220 다음 경고는 오류로 처리됩니다. simpleble chrono.h
사진 아래 경고는 딱히 상관없다. 그냥 인코더 오류인 것 같은데.. (아까는 안뜨던데..)
어쨋든 chrono.h가 뭔 문제인지 경고가 뜨는거다. simpleble 프로젝트를 보면 chrono.h가 fmt/chrono.h에 있다고 분명 정의가 되어있고 아무 문제가 없는 것 같은데도 저런 오류가 뜬다. 근데 저건 경고인데 오류로 처리한거라 그냥 무시하도록 바꾸면 된다.
simpleble 프로젝트를 오른쪽 클릭하고 속성에 들어간다.
그럼 대충 이런식으로 뜰텐데
여기에서 왼쪽 리스트에서 C/C++ 안에 일반에 보면 사진처럼 경고를 오류로 처리는 항목이 있다.
이거 떄문에 아까 오류가 뜬건데 그냥 아니요(/WX-)로 바꾸면 된다.
그 후에 확인을 눌러서 저장하고 다시 simpleble 프로젝트 오른쪽 클릭해서 빌드 눌러서 빌드한다.
그러면 정상적으로 빌드가 되게 된다.
이런식으로 아래에 출력창에 뜬다.
이제 필요한건 다 빌드 했으니 ALL_BUILD를 빌드하면 된다.
똑같이 그냥 ALL_BUILD 프로젝트를 오른쪽 클릭하고 빌드 버튼 눌러서 빌드 하면 된다.
이건 좀더 많이 오래걸린다.. 전부 빌드해야해서..
다 하면 이렇게 3분 동안 빌드한게 뜬다..
이제 마지막으로 이걸 한 폴더안에 전부 모을 수 있게 프로젝트를 빌드해야하는데 바로 INSTALL 프로젝트이다.
이것도 그냥 똑같이 INSTALL 프로젝트를 오른쪽 클릭해서 빌드 버튼 눌르고 빌드하면 된다.
(만약에 혹시 setlocal인가 하는 오류 뜨면 위에 못보고 지나친 글 보면 된다.)
이렇게 하면 위에서 말한 대로
C:/Users/pkdpm/Downloads/brainflow/install
사전에 CMake에서 설정한 곳에 빌드된게 생긴다. inc 와 lib 폴더이다. 어떤 역할인지는 대충 폴더 보면 알 수 있고.. 암튼 이거를 사용할 수 있게 어디 C 안에 두면 된다.
나 같은 경우는 전에 VCPKG 설치하면서 만들어 두었던 dev 폴더에 넣기로 했다.
C:/dev/brainflow
나는 이 폴더에 inc와 lib 폴더를 넣었다.
예제 프로젝트 만들어서 실행해보기
이제 잘 되는지 테스트 해보기 위해 프로젝트를 만들어서 실행해봐야 한다.
일단 Visual Studio를 실행한다.
새 프로젝트 만들기 해서 빈 프로젝트를 하나 만든다.
소스 파일 오른쪽 클릭해서 새 파일로 main.cpp 파일 만들고 그 안에 아래 링크에 있는걸 복사해서 붙인다.
(참고로 이후에 프로젝트 진행하면서 MD로 빌드 해야해서 해보니 CMake로 Open Project 했을 때 열리는 것에서 오른쪽 ALL_BUILD 등등의 프로젝트 속성에서 C/C++의 코드 생성에서 런타임 라이브러리를 모두 MD로 바꿔주고 빌드하면 MD로 빌드된다.)
그 후에 확인 버튼을 눌르고 다시 실행한다! 실행하는건 Ctrl + F5로
그러면 드디어 빌드가 되고 실행이 된다!
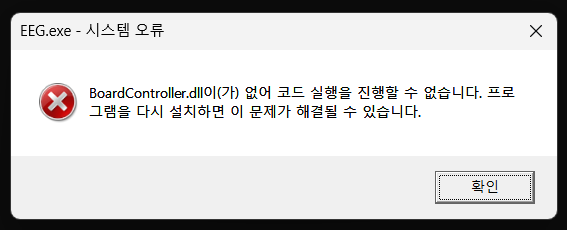
근데 이런식으로 오류가 뜨게 된다.
컴파일 한걸 실행할려는데 DLL 파일이 없어서 안되는거다. 그냥 옮기면 된다.
아까전에 빌드 했던거 옮겨놓은 폴더에 가서 lib 폴더로 들어간다.
그러면 .dll로 되어있는 파일들이 여러개 보이는데 뭐인지 확인하는건 귀찮으니깐 .dll로 되어있는 파일은 모두 복사한다.
(Ctrl 키 눌르고 여러개 선택해서 복사하면 된다.)
붙여 넣는 곳은 프로젝트를 오른쪽 클릭해서 파일 탐색기에서 폴더 열기(X) 버튼을 눌른 후 뜨는 폴더에 다 붙여넣으면 된다.
그렇게 되면 이렇게 붙여넣어졌을 것이다.
이러면 끝이다!
이제 Muse 제품의 전원을 키고 실행해보면? 정상적으로 연결이 된다!
실행하면 아래처럼 뜨는데
Found Muse device, Connected to Muse Device 이거 뜨면 정상적으로 연결된거다!
이렇게 된 후에는 자동으로 10초간 정보가 기록되고
이렇게 csv 파일로 기록이 된다!
만약에 연결이 안되거나 하면 전원을 켜보거나 자신의 PC에 블루투스 동글이나 블루트스 연결할 수 있는 장치가 있는지 확인해보는걸 추천한다..
마무리
그리고 csv에 저장된건 사실 봐도 지금은 뭔지는 모르겠다.. 일단 연구 과제가 이걸로 뭐 UI 만들어서 기록하도록 만드는건데 암튼 이걸 할려고 좀 이상한 짓을 한 것 같다.. 그냥 파이썬을 커맨드 라인으로 실행해서 하는 것도 빨랐을지도.. (뭐 시간이 중요해서 이렇게 하는거지만..)