우선.. 한가지 말하자면.. 나는 이 블로그에서 전에 Yolo V5를 학습하는 설명을 하다가 말았던 적이 있다..
2022년 (고2) 때 쓰던건데.. 중간에 그만 둬서.. 2025년 이번에 다시 써볼려 한다..!
YOLO 란?
YOLO 모델은 간단히 말하면 객체 인식 인공지능 모델 중 하나이다. (YOLO(You Only Look Once) 이건 그냥 모델의 이름;;)
YOLO는 2015년에 Yolo V1 출시로 지금까지 있으며, 현재 마지막으로 출시한건 Yolo V12이다.
특이한건 Yolo V12가 출시는 했으나 아직 Yolo 깃허브에는 V11로 등록이 되어있다.
그래서 이번껀 V11로 학습해볼 것이다. 다만 V11과 V12의 학습 방법의 차이는 그냥 이름만 변경하면 되는거라서 똑같이 진행하면 된다.
참고로.. 2022년 정도 까지만 해도 Yolo V5를 많이 사용해왔고.. 현재도 Yolo를 검색해보면 대부분 Yolo V5가 나온다..
내가 알기론 여러 기관에서도 Yolo V5를 많이 사용 한다고도 알고 있고.. 그 이유는 Yolo V5의 성능이 좋기도 하고 다른 버전에 비해 커뮤니티가 활발하기에 그렇다고 생각된다..
하지만 Yolo V11은 확실히 좋기는 하다.. 속도도 빨라졌고.. 모델 성능도 더 좋아진 것이 체감될 정도이다..
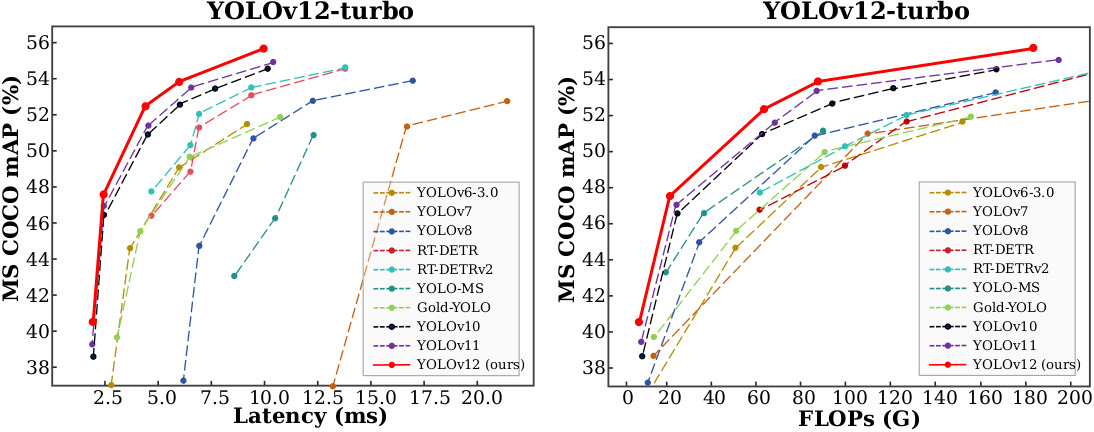
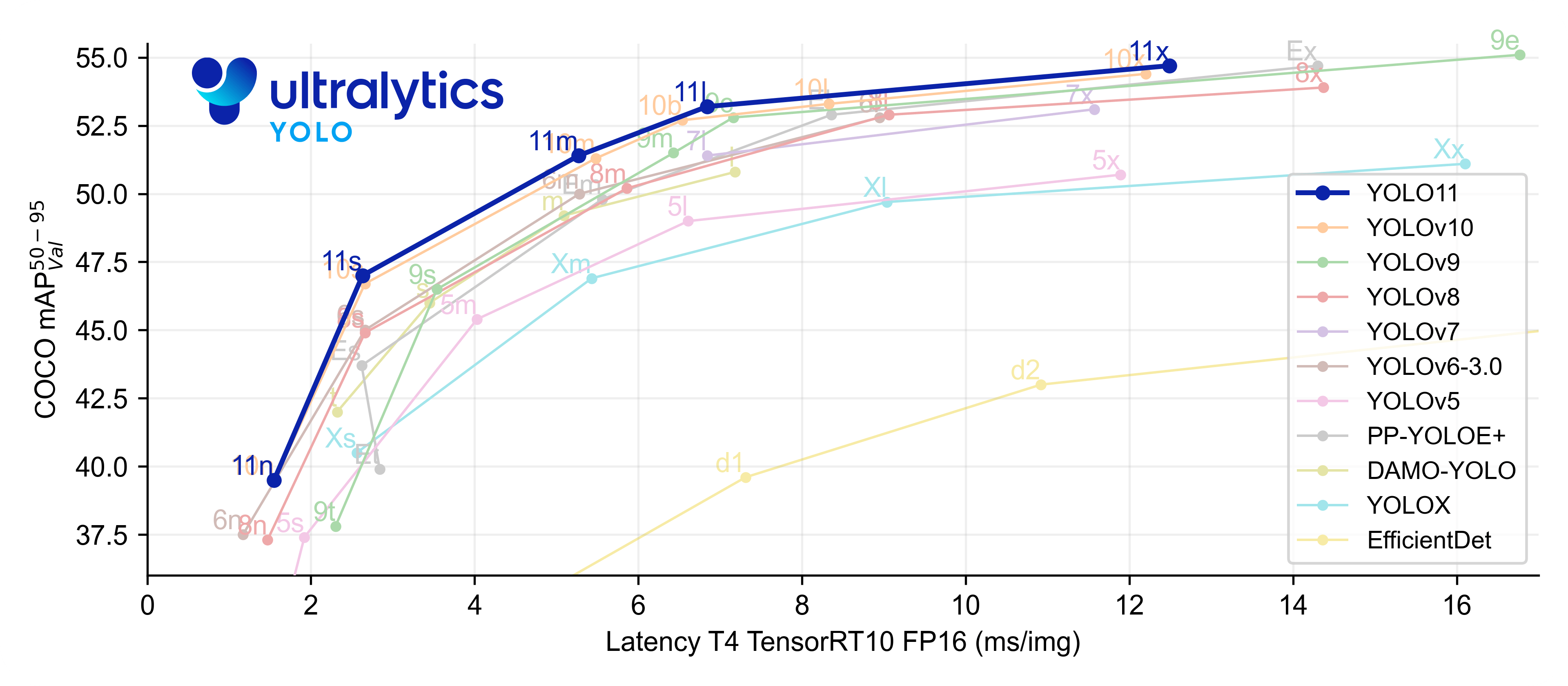
여기 표를 보면 알 수가 있는데.. 일단 첫번째 이미지는 그냥 Yolo V5는 없지만 Yolo V12는 있어서 넣은 사진이고 두번째 이미지는 Yolo V5는 있지만 Yolo V12는 없어서 같이 올렸다.
여기에서 Latency는 추론 속도이다. FLOPs는 딱히 알 필요는 없지만 연산 개수이다. 추론할 때 내부에서 몇번을 계산하는지.. 그냥 모델 크기로 이해해도 될 것 같다. Latency, FLOPs는 왼쪽으로 낮으면 좋다.
마지막으로 COCO mAP는 Yolo의 모델은 Coco 라는 데이터셋으로 학습이 되어있는데.. 그 데이터셋으로 객체 인식을 했을 때 얼마나 정확한지 라는 것이다. 높으면 좋다.
아무튼 그렇게 두고 보면 Yolo V12가 역시 좋긴 하다.. 하지만 아직 제대로 출시는 안한 것 같으니.. 이번에는 넘어가는데..
Yolo V11과 Yolo V5를 비교하면 확실히.. Yolo V11를 안쓰기에는 성능이 꽤 차이난다는 것이다.
모델 크기
그리고 저 위에 사진을 보면 각 모델 뒤에 n, s, m, l, x 이건 모델의 크기이다.
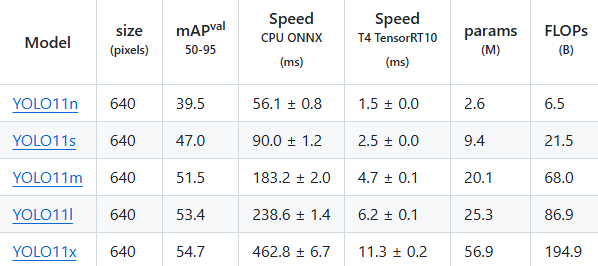 |
이게 각 모델의 크기이다.
Nano, Small, Medium, Large, X-Large의 앞 글자를 딴 것이다.
모델이 커질 수록 속도가 느리지만.. 정확도는 올라간다. 하지만 걱정하지 않아도 될껀.. X Large 모델까지 가는 경우는 간단한 프로젝트에선 별로 필요없다는 것이다. 보통은 Nano나 Medium 모델 정도 까지만 쓰이고 그 이외에는 진짜 제대로 예측해야한다..
몇십만장 데이터셋을 학습해서 해야한다.. 이정도일 때 정도이지.. 간단하게 예측하는 용도라면 X Large 까지 선택할 이유는 없다. 오히려 학습을 더 많이 해야하기도 하고 속도도 쓸데 없이 느리고.. 데이터셋이 충분하지 않다면.. 오히려 좋지 않다..
그렇기에 여기에서는 Nano로 진행할 것이다..!
참고로 저기에 보면 size라고 나와있는건.. 괄호 안에 pixels를 봤겠지만.. 말 그대로 픽셀의 개수이다..
모델의 용량이라고 생각하면 안된다.
Yolo는 다양한 픽셀을 받아서 추론할 수가 없다. 대부분의 모델도 그렇겠지만.. 이미 모델의 크기는 확정되어있기 때문에.. 딱 지정된 크기의 사진만 받아서 처리한다.
그렇기에 만약 내가 1920 * 1080의 사진을 추론할려고 하면.. Yolo V11 Nano 모델이 640 size이니 1920 * 1080px를 640 * 640px으로 변경한 후 모델로 넣어서 추론을 한다는 것이다. 마찬가지로 270 * 320px 이런 이미지를 넣으면 강제로 640 * 640px 이미지로 변경해서 추론을 한다.
작은 객체 탐지..?
이러면 한가지 의문이 들 수 있다.. 만약 큰 해상도의 이미지에서 작은 객체를 탐지할려는 경우.. 이미지가 축소되고 객체가 손실되어 작아지는 경우 탐지하기가 어려운거 아니야? 라고 생각할 수 있는데.. 정답이다.
Yolo 로는 작은 객체를 탐지하기가 매우 어렵다. 대부분의 인공지능 모델도 이걸 해결하기는 쉽지가 않다..
물론 모델의 이미지 입력 크기를 늘리면 되긴 한다.. 하지만 그렇게 되면 모델을 다시 처음부터 학습해야하기도 하고.. 작은 객체를 찾을 순 있겠지만 굉장히 느리고.. 기존에 640 * 640으로 맞춰 설계된건데.. 늘려서 학습하게 되면 구조가 또 잘 안맞아.. 오히려 정확도가 떨어질 수도 있다..
https://shaunyuan22.github.io/SODA/
SODA: A large-scale Small Object Detection dAtaset
Small Objects, Big Challenges.
shaunyuan22.github.io
그래서 이런 것들도 있다.
아무튼 작은 객체인 경우 무조건 못 찾는다고 볼 수는 없다..
알고리즘이지만 다른 기법이 있다. SAHI 라는 기법이 있다.
나중에 시간이 된다면.. SAHI에 대해서도 쓰겠다만.. 간단하게 말하면 큰 이미지를 나눠서 추론하고 결과를 합치는 방법이다. (물론 나눈 만큼 전부 추론해야하기 때문에 시간이 나눈 만큼 늘어난다는게 함정이다..)
https://docs.ultralytics.com/ko/guides/sahi-tiled-inference/
SAHI 타일형 추론
슬라이스 추론을 위해 SAHI로 YOLO11 구현하는 방법을 알아보세요. 대규모 애플리케이션의 메모리 사용량을 최적화하고 탐지 정확도를 향상하세요.
docs.ultralytics.com
타일로 나누는 경우 객체가 반쪽 반쪽 인식되어서 한개의 객체가 2개 이상으로 탐지 되는 경우도 저기에선 해결했다. 그냥 겹쳐서 탐지한 후에 알고리즘으로 합친다..
뭐 아무튼 저런 것도 있다는걸 알아두면 좋을 것 같다..
학습에 대한 것
마지막으로 이제부터 쓸 학습에 대한 것인데..
우선 YOLO는 기본적으로 COCO 데이터셋으로 학습되어있고.. 학습된 객체는 매우 많다.
https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml
ultralytics/ultralytics/cfg/datasets/coco.yaml at main · ultralytics/ultralytics
Ultralytics YOLO11 🚀. Contribute to ultralytics/ultralytics development by creating an account on GitHub.
github.com
아마 저 링크에 나와있는데로 기본 모델은 80개의 객체를 탐지할 수 있는걸로 알고 있다.
그래서 만약에 자신이 탐지할려는게 저기에 나와있는 범용적인 것이라면 그냥 기본 모델을 쓰면 된다. (물론 기본 모델은 여러 객체 탐지를 목표로 하기에 딱 한개만 탐지할려는 경우 따로 학습하는 것 보다 정확도가 떨어질 순 있다.)
하지만 저 리스트에도 없고 새라는 것 중에 빨간 새 이런 딱 확실하게 어느 하나를 탐지할려고 한다면.. 학습을 하는 것이 좋다..
근데 모델을 학습하는 방법은 2가지 정도가 있는데.. 하나는 완전 처음부터 학습하는 것이고, 하나는 파인튜닝이라고 기존에 학습된 모델을 내 데이터셋에 맞추도록 하는 것인데..
파인튜닝을 쓰면 처음부터 학습하는게 아니기 때문에 내 데이터셋을 학습할 때 더욱 빨리 학습할 수 있게 된다.
그래서 새로 학습을 할 때 1000번 학습한다면.. 파인튜닝은 50~100번 정도만 학습해도 정확도가 1000번 학습한 것 보다 높아질 수 있다. (물론 데이터셋의 종류와 양에 따라 다르겠지만..)
그리고 파인튜닝을 하면.. 내가 설정한 데이터셋에 대해서만 탐지하고 기존에 학습된 것 들은 더 이상 탐지할 순 없다.
아무튼 그렇기에 나는 파인튜닝을 하는 방법에 대해서 작성할 것이다.
어차피 새로 학습하는 것과는 방법에는 별 차이가 없긴 하다..
찐막
그리고 진짜 마지막으로 말할껀.. 내가 자주 YOLO를 탐지가 아닌 추적이라고 쓸 때가 있는데.. 일단 여기에선 탐지라고 썼지만.. 실수로라도 추적이라고 쓸 수도 있다.. 그냥 내 실수이긴 하지만.. (그냥 추적이라고 적혀있으면 탐지라고 보면 된다..)
추적은 객체가 이동하는걸 추적할 때를 말하는거고..
탐지는 객체가 있다는 것만 알 수가 있다.
즉 동영상에서 특정 객체가 어디로 이동하는지 알려면 추적을 해야하는거고.. 그냥 동영상에서 어떤 객체가 있는지만 볼려면 탐지를 해야한다는 것이다.. (분명 다른 단어인데.. 나는 자주 실수로 같이 쓸 때가 있다..)
YOLO는 객체를 추적할 순 없고 탐지만 가능하다..
추적을 할려면.. 알고리즘으로 하는 방법도 있고.. 인공지능으로 하는 방법도 있으니.. 잘 찾아보시길..
그리고 두번째로 말할껀
YOLO에는 탐지만 할 수 있지만.. 탐지할 수 있는 종류가 꽤 여러가지이다.
https://docs.ultralytics.com/ko/tasks/
Ultralytics YOLO11 지원하는 컴퓨터 비전 작업
Ultralytics YOLO11 에서 높은 정확도와 속도로 감지, 세분화, 분류, OBB 및 포즈 추정 기능을 살펴보세요. 각 작업을 적용하는 방법을 알아보세요.
docs.ultralytics.com
저 위에 사이트에 들어가면 뭐를 탐지할 수 있는지 종류가 나와있다.
YOLO는 Detect, Segment, Classify, Pose, OBB를 지원한다.
Detect는 이번 글에서 진행할 방법이고..
Segment는 딱 객체가 차지하고 있는 그 부분만 찾는거고..
Classify는 이미지를 넣었을 때 그 이미지 자체가 고양이인지 개인지 이런걸 분류하는거고..
Pose는 인간의 포즈가 어떻게 된건지.. 뭐 다른 동물도 학습하면 가능할테고..
OBB는 객체를 탐지하는건 같지만 어느정도 회전했는지도 감지하는 것이다.
마무리
아무튼 이제 설명은 끝났고..
다음 글 부터는 데이터셋을 만들고.. 데이터셋을 학습하는 방법에 대해 설명을 할 것이다..!
솔직히.. 코드 같은건 작성할게 거의 없기 때문에.. 코딩을 모르는 경우에도 쉽게 할 수 있을 정도로 간단하다..!
물론 노가다 작업들이 있긴 하지만.. 시간을 투자하면 충분히 가능..!
암튼 그렇다..!
'AI > YOLO' 카테고리의 다른 글
| YOLOV5 윈도우로 돌리기 Part.3 (데이터 준비하기) (0) | 2022.07.20 |
|---|---|
| YOLOV5 윈도우로 돌리기 Part.2 (Anaconda, Visual Studio Code 기본 설정) (0) | 2022.07.20 |
| YOLOV5 윈도우로 돌리기 Part.1 (잡담과 아나콘다 비쥬얼 스튜디오 코드 설치!) (0) | 2022.07.19 |