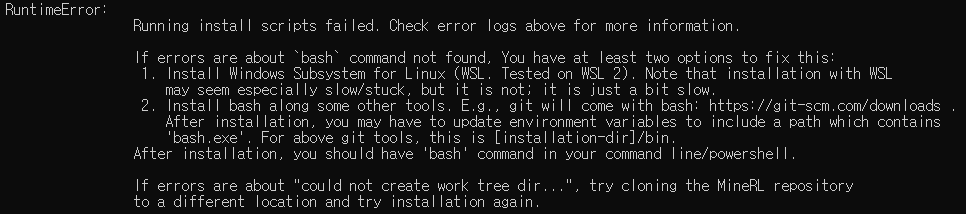
서론
2025년 2월 27일 Sesame AI (참깨 AI?)에서 굉장히 현실적인 목소리의 음성 대화 모델을 출시했다고 했다.
Demo 도 출시했었는데, 실제로 써보니깐 퀄리티가 엄청나게 좋았었다. 실시간 대화는 기본이고 ChatGPT의 초기 보이스 모드 처럼 대화하면서 웃는다거나 울거나 노래를 불르는 진짜 사람과 대화하는 것 같은 모델이 나왔었다. (다만 말이 너무 많은..)
다만 영어 모델만 지원하고 있었어서 내가 직접 사용하기에는 어려웠고 영어를 제일 잘하는 친구에게 시켜보았었는데.. 굉장히 대화를 잘 하고 있었고.. 대화 중에 웃거나 한숨을 쉬거나 여러 특이한 장면들도 볼 수 있었다.
대화가 끝난 후 물어보니 약간 대화의 흐름을 잘 파악하지 못하는 것 같은 느낌은 있었지만 진짜 사람 같고 자연스러운 대화 같았다고 했었다.
일본어나 한국어를 시켜볼 때는 약간 하기 싫어하는 느낌으로 끊어서 "お、は、よ、う、ご、ざ、い、ま、す” 같은 느낌으로 끊어서 한자리씩 천천히 말하기도 했었다.
참고로 말이 엄청 빠르고 말이 많기 때문에 영어를 원어민 처럼 잘하는게 아니라면 AI도 이해를 잘 못하고 자신도 이해를 못하는 것을 경험할 수 있을 것이다;;
실제로 대화해보실 분은.. 여기 링크로! https://www.sesame.com/research/crossing_the_uncanny_valley_of_voice#demo
Crossing the uncanny valley of conversational voice
At Sesame, our goal is to achieve “voice presence”—the magical quality that makes spoken interactions feel real, understood, and valued.
www.sesame.com
다만 대화하는데 통화 품질 검토를 위해 녹음한다고는 한다. (학습에는 사용되지 않는다고 하지만.. 그건 잘 모르겠다.)
https://www.sesame.com/research/crossing_the_uncanny_valley_of_voice
Crossing the uncanny valley of conversational voice
At Sesame, our goal is to achieve “voice presence”—the magical quality that makes spoken interactions feel real, understood, and valued.
www.sesame.com
여기에서 설명하는 것으로는 앞으로 언어 지원을 20개 이상 추가한다고 한다. 아마도 그 중에는 한국어도 포함 되어있을꺼라 생각된다..
그리고 모델의 크기는 굉장히 작은
- Tiny: 1B backbone, 100M decoder
- Small: 3B backbone, 250M decoder
- Medium: 8B backbone, 300M decoder
이 정도의 모델 사이즈를 가지고 출시된다고 한다.
그리고 라이센스가 Apache-2.0 license 라이센스 이기 때문에, 상업적으로 사용하거나 학습하는 것에 문제는 없는 것 같다. 다만 사기나 이런 곳에는 사용하지 않는 것이 좋다고 적혀있다. github 아래에.. (당연한거지만)
본론
암튼 이 모델이 출시되기를 엄청 기다렸다..!!
https://x.com/_apkumar/status/1895492615220707723
위 글을 보면 출시가 2025년 3월 1일 기준으로 1 ~ 2주 안에 출시된다고 하고.. 현재 글을 쓰는 시점으로 20시간 전에 출시를 했다..! (현재 시간은 2025년 3월 15일 1시 40분)
암튼 이제 설치부터 해보는걸로!
일단 우선 Github 링크이다.
https://github.com/SesameAILabs/csm
GitHub - SesameAILabs/csm: A Conversational Speech Generation Model
A Conversational Speech Generation Model. Contribute to SesameAILabs/csm development by creating an account on GitHub.
github.com
GIthub 링크에도 설치 방법이 잘 나와있다. 그렇기 때문에 나는 2가지 방법으로 해볼 것이다. 처음은 Windows 두번째는 WSL로
HuggingFace 모델 권한 요청
일단 먼저 HuggingFace에 모델 사용 권한 허락 부터 받아야 한다.. 반드시 이걸 먼저 해준 후 진행해야한다.
https://huggingface.co/meta-llama/Llama-3.2-1B
https://huggingface.co/sesame/csm-1b
sesame/csm-1b · Hugging Face
This model is not currently available via any of the supported Inference Providers. The model cannot be deployed to the HF Inference API: The model has no library tag.
huggingface.co
CSM-1B 모델의 경우 그냥 사이트 가서
아래의 Agree and access repository를 눌르면 바로 사용할 수 있도록 권한을 얻을 수 있다.
다만 Llama의 경우는 좀 어렵다.
이렇게 떠 있을 텐데
Expand to review and access라 나오는걸 눌르면 그 아래에
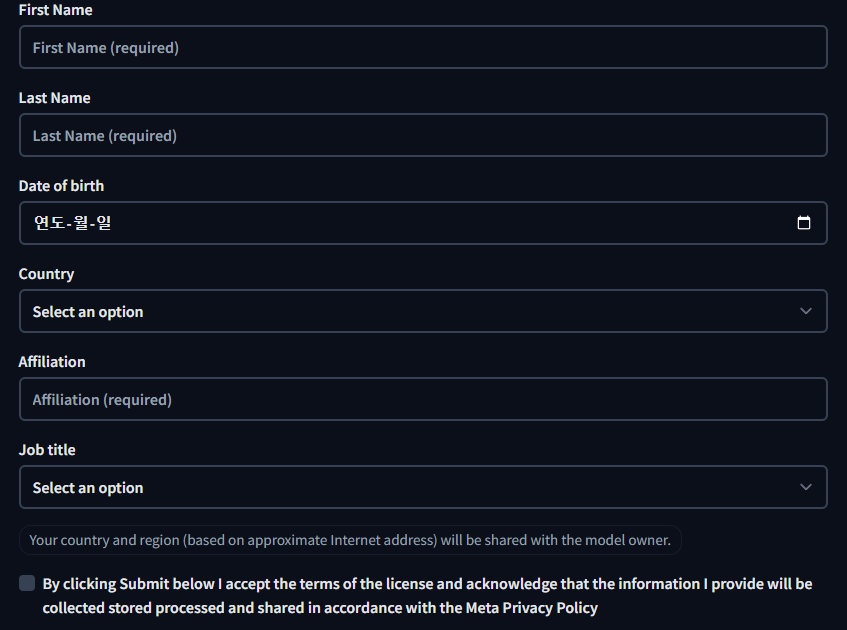
이렇게 입력하는 창이 나오는데 전부 제대로 입력해야한다. 그 후 메타에서 승인해줄 때 까지 기다려야 한다. 대충 1시간 이내로 요청을 허락해준다.
다만 귀찮다고 대충 쓰면 안된다. 제대로 써야만 허락을 해준다.
(며칠전에.. 친구가 귀찮다고 대충 쓰고 영원히 그 계정에선 요청 권한이 사라진..)
Windows에서 설치 방법
암튼 먼저 Windows 부터!
Windows 같은 경우 제대로 지원하지는 않기에 조금 방법이 까다롭고 굳이이긴 하다.. WSL로 설치하는걸 가장 추천..
일단 Github에 설치하는 방법이 있지만 그걸 따르기는 좀 애매하다. Linux에서 설치하는 방법이기 때문에..
암튼 먼저 가상환경 부터 만들자! (Python 버전의 경우 Github에 나와있다.)
conda create -n csm python=3.10 -y
그 후 가상환경을 활성화 시킨다!
conda activate csm
그리고 csm github 레포를 다운한다. (아래 설치에선 requirements.txt를 사용하여 설치는 안하지만 다른 파일들을 사용하기에 미리 cd로 접근한 것이다.)
git clone https://github.com/SesameAILabs/csm.git
cd csm
그 후 필요한 라이브러리를 설치해야한다.
pip install tokenizers==0.21.0 transformers==4.49.0 huggingface_hub==0.28.1 moshi==0.2.2 torchtune==0.5.0 torchao==0.9.0 bitsandbytes==0.45.3 triton-windows==triton-windows==3.2.0.post13 silentcipher@git+https://github.com/SesameAILabs/silentcipher@master
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126Windows의 경우 지원안하는 것이 좀 있기에 따로 설치해줘야 하는것이 있다. 그리고 silentcipher 이 라이브러리를 따로 설치하는데.. 이 라이브러리에 가보면 torch를 2.4.0으로 설치하게 되고.. 이 CSM Github에서도 2.4.0을 설치한다. 그래서 깔꺼 전부 깔고 난 후에 torch를 새로 설치하는 것이다. 아마도 2.x.x 버전이면 다 될 것 같다.
암튼 이렇게 하면 바로 설치가 끝난다..!
WSL에서 설치 방법
일단 WSL에서 설치하기 전에 Anaconda와 Cuda, Cudnn을 설치한다. 아래 링크에 가서 따라서 설치하면 된다.
https://www.anaconda.com/download/success
https://developer.nvidia.com/cuda-downloads (https://docs.nvidia.com/cuda/wsl-user-guide/index.html)
https://developer.nvidia.com/cudnn-downloads
다 설치를 한 후에 아래 방법을 하면 된다. 좀 더 간단하다..!
암튼 먼저 가상환경 부터 만들자! (Python 버전의 경우 Github에 나와있다.)
conda create -n csm python=3.10 -y그 후 가상환경을 활성화 시킨다!
conda activate csm그리고 csm github 레포를 다운한다. 그 후 csm 폴더로 접근한다. (이전 Windows와 다르게 csm 폴더에 있는 requirements.txt를 사용하여 다운하기 때문에 폴더 접근이 필요하다.)
git clone https://github.com/SesameAILabs/csm.git
cd csm그 후 필요한 라이브러리를 설치해야한다.
pip install -r requirements.txt
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126그리고 나는 torch는 따로 설치해줬다. 2.4.0으로 써도 되긴 하지만, 좀 찝찝해서 2.6.0으로 추가 설치했다.
암튼 이러면 WSL도 설치는 다 끝난다..
이제부턴 코드를 실행해볼 것이다! 다만 그 전에 HuggingFace에서 토큰을 발급받아야 해서 그것부터 해봐야 한다.
HuggingFace Token 발급
여기에서 필요한 2개의 llama 모델과 csm 모델을 다운받기 위해선 권한이 필요하기에 그 권한을 받은 계정으로 로그인을 해야한다. 로그인 방법은 Token을 발급해서 코드에서 쓸 수 있도록 하면 되는데 발급 방법은 간단하다.
https://huggingface.co/settings/tokens
Hugging Face – The AI community building the future.
huggingface.co
여기 링크로 접속을 한다.
그 후에
오른쪽 상단에 Create new token이라는 표시가 있을 것이다. 그걸 누른다.
그러면 다른 창으로 가지는데
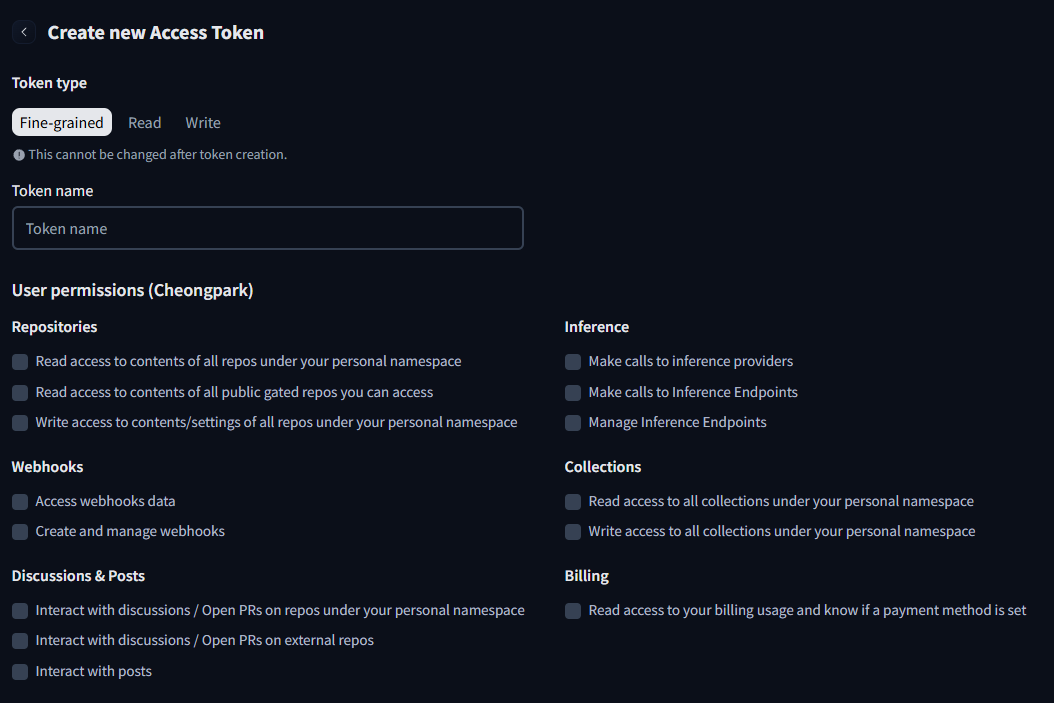
이런 창이 보일 것이다. 이거는 딱히 필요없고.. Fine grained 바로 오른쪽에 Read 라는 버튼이 있다. 그걸 눌르면 된다.
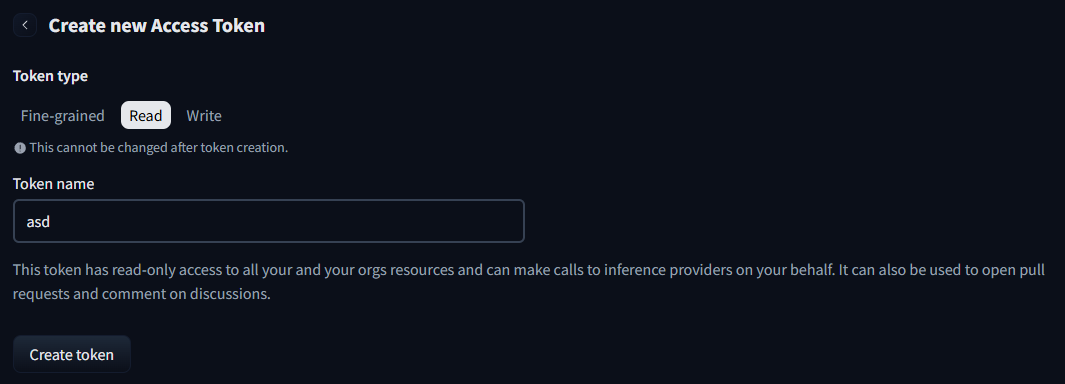
그러면 이렇게 Token name 인 토큰 이름 적는게 나오는데 그냥 아무 이름 적으면 된다. 나는 간단히 하기 위해 그냥 "asd"로 입력했다. 그 후 아래에 Create token을 누른다.
그 후에는 토큰이 바로 나오는데, 알 수 없는 영어들이다. 그냥 그 오른쪽에 있는 Copy 버튼을 눌르면 토큰이 복사된다. 그렇게 가지고 있으면 된다. 만약에 까먹었으면 저 위에 링크 다시 가서 만들었던 토큰을 복사하면 된다.
이제 다 됬으니 바로 코드를 실행해보는걸로..!
코드 실행
코드 같은 경우 github에 적혀있지만.. 간단하게만 적어둬서 실행할려면 좀 python을 알아야 한다.
근데 뭐 그냥 아래 코드 복사하면 된다.
from huggingface_hub import hf_hub_download
from generator import load_csm_1b
import torchaudio
import os
import time
os.environ["HUGGING_FACE_HUB_TOKEN"] = "위에서 얻은 Token 그대로 이 문장 지우고 붙여넣기"
print("Model Loading...")
start_time = time.time()
model_path = hf_hub_download(repo_id="sesame/csm-1b", filename="ckpt.pt")
generator = load_csm_1b(model_path, "cuda")
print(f"Model Loading Complete: {time.time() - start_time:.2f}s")
print("Audio Generation Start...")
start_time = time.time()
audio = generator.generate(
text="Hello from Sesame.",
speaker=0,
context=[],
max_audio_length_ms=30_000,
)
print(f"Audio Generation Complete: {time.time() - start_time:.2f}s")
print("Audio Saving...")
start_time = time.time()
torchaudio.save("audio.wav", audio.unsqueeze(0).cpu(), generator.sample_rate)
print(f"Audio Saving Complete: {time.time() - start_time:.2f}s")
좀 더 쉽게 알 수 있게 시간도 측정할 수 있도록 추가했다.
그리고 출력하는건 한국어도 할 수 있지만.. 폼이 안나기에 영어로..
일단 우선 알아야 할 것이 있다.
이 코드는 반드시 아까 다운로드한 csm 레포 안에다가 파일을 생성하고 거기에 붙여서 실행해야한다.
이유는 이용해야하는 파일이 그 폴더에 있기 때문..
그리고 코드에 보면
audio = generator.generate(
text="Hello from Sesame.",
speaker=0,
context=[],
max_audio_length_ms=30_000,
)이 부분이 제일 중요하다.
text는 말 그대로 그냥 음성으로 바꿀 텍스트이고
speaker은 아마 말할 화자가 누구인가 일 텐데.. 이건 이후 다른 코드에서 쓰인다. 일단 위 코드는 간단하게 1명만 말하는 코드이기에 0으로 설정하면 된다.
context도 이후 다른 코드에서 쓰인다. 이것도 누구 화자인지에 대한 것을 설정할 때 쓰인다.
max_audio_length_ms 이게 가장 중요하다. 몇초를 만들게 할지이다. 내가 설정해놓은건 30초인데 그냥 앞에 2자리 숫자만 바꿔서 숫자를 늘리거나 줄이면 된다.
나는 문장도 길게 입력할 것이기에 적당히 늘려놓았다. (어차피 AI가 알아서 다 말하면 끊어버리기 때문에 그냥 길게 놓아도 상관은 없다.)
그리고 아까 복사했던 HuggingFace Token은 입력하라는 곳에 그대로 입력하면 된다.
그 후에 바로 실행해보면 된다..!
참고로 GPU는 6GB 이상은 필요하다. 그냥 적당히 8GB 이상은 되게 해야한다.
만약 그래픽카드가 부족하거나 없다면.. 그냥 CPU도 가능은 할 것이다. torch를 cpu 버전으로 깔았다면
암튼 실행!
/home/cheongpark/anaconda3/envs/csm/lib/python3.10/site-packages/pydub/utils.py:170: RuntimeWarning: Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work
warn("Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work", RuntimeWarning)
Model Loading...
ckpt path or config path does not exist! Downloading the model from the Hugging Face Hub...
Fetching 13 files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:00<00:00, 198276.19it/s]
Model Loading Complete: 12.54s
Audio Generation Start...
Audio Generation Complete: 4.94s
Audio Saving...
Audio Saving Complete: 0.01s실행해보면 이렇게 영어가 이상하게 나오면서 정상적으로 실행이 된다..! 물론 이 전에 모델을 한번 다운 받고 실행하게 된다. 모델은 대충 6GB이다.. 만약 모델 다운 받을 때 다운 안되면 Token 제대로 발급 안했거나 Read로 발급 안했을 때 발생한다. 아니면 라이브러리 잘 못 깔았던지..
그리고 소리를 들어보면..
이렇게 잘 된다..!
그리고 목소리의 경우 실행할 때 마다 바뀐다.. 저건 뭔가 빵 먹으면서 말하는 것 같은데..
똑같은걸 다시 실행하면 이렇게 된다.
테스트 및 Windows와 WSL 속도 비교
한번 Windows와 WSL의 속도 차이를 비교해볼 것이다.
우선 내 컴퓨터 사양을 말하자면..
CPU : AMD 5900X
RAM : Samsung DDR4 32GB 3200
GPU : MSI RTX 3080 TI
이다.
어차피 코드하고 GPU 이런거는 다 같기 때문에 소리는 거의 차이 없을 것이고.. 그냥 단순히 실행 속도를 비교한다면..
| Windows Model Loading... Model Loading Complete: 16.23s Audio Generation Start... Audio Generation Complete: 7.19s Audio Saving... Audio Saving Complete: 0.00s |
WSL Model Loading... Model Loading Complete: 13.42s Audio Generation Start... Audio Generation Complete: 4.84s Audio Saving... Audio Saving Complete: 0.01s |
대충 이렇다. Windows가 살짝 더 느리다..
그리고 이번에는.. 아까 설정했던 text에 따로 ChatGPT 한테 말해서 생성한 문장을 넣고 max_audio_length_ms를 60_000으로 설정해서 실행해볼 것이다.
문장의 경우 아래 문장을 사용했다.
Hi, I’m Robi!
Nice to meet you!
I’m Robi, a friendly robot designed to make life more fun and interactive.
I can walk, talk, dance,
and even understand your feelings!
I respond to your voice and can have simple conversations with you.
I’m made up of over 70 parts,
and I was built step-by-step using a special magazine series.
My design allows me to express emotions
through my eyes and gestures,
making me feel more lifelike.
I’m powered by a sophisticated control board and motors
that help me move smoothly.
My speech recognition lets me understand commands,
and I can even learn new things over time.
I’m always ready to chat, play,
and keep you company.
Let’s have fun together!참고로 문장 넣을 때는 "문장" 이렇게 쌍따옴표 한개로 하면 한줄로만 작성할 수가 있고..
'''문장''' 이렇게 따옴표를 3개씩 해두면 여러 줄에 걸쳐서 입력할 수 있다. 여러줄에 걸쳐서 입력하는게 좋긴 하다.
암튼 실행해보면!
Windows (파일 크기 : 4.15MB)
WSL (파일 크기 : 3.7MB)
이렇게 출력된다.
나는 추가로 여기에는 Seed를 설정을 따로 할 순 없지만.. 토치나 이런거는 가능하기에 그건 Seed를 설정했다. 그래서 음성은 그나마 비슷하나.. 다른 곳에선 Seed 영향을 안받는 것이 있을 것이기 때문에.. 위 오디오 처럼 약간만 비슷하다.
그 시드 설정을 안하면 아예 똑같은 느낌도 아니긴 하다..
암튼.. 생성이 잘 못 되었는지.. 음성이 조금 깨져서.. 별로긴 하다..
이것도 속도 비교를 해보면..
| Windows Model Loading... Model Loading Complete: 22.65s Audio Generation Start... Audio Generation Complete: 149.14s Audio Saving... Audio Saving Complete: 0.04s |
WSL Model Loading... Model Loading Complete: 15.53s Audio Generation Start... Audio Generation Complete: 115.58s Audio Saving... Audio Saving Complete: 0.01s |
이렇게 확실하게 차이가 나는 것 같지만.. 파일 크기를 보면 다르기에.. WSL이나 Windows나 WSL이 좀 더 속도가 빠르긴 하지만 거의 비슷하다는 것을 알 수 있다. 30초 정도의 차이는 파일 크기에 비례하는걸로.. 생각하는걸로..
이것 외에 추가로 테스트 해보면 똑같은 문장을 생성을 잘 해본게 있는데..
이건 깔끔하게 잘 되었다..!
그리고 2번째 테스트!
2번째 코드
이 코드는 첨부만 하고 딱히 실행은 안해볼 것이다. 실행을 해보긴 했지만.. 좋긴 하나 실행하는 것에 어렵기도 하고.. 글 쓸 시간도 부족해서..
from huggingface_hub import hf_hub_download
from generator import load_csm_1b
from dataclasses import dataclass
import torch
import torchaudio
import os
@dataclass
class Segment:
text: str
speaker: int
audio: torch.Tensor
os.environ["HUGGING_FACE_HUB_TOKEN"] = "위에서 얻은 Token 그대로 이 문장 지우고 붙여넣기"
model_path = hf_hub_download(repo_id="sesame/csm-1b", filename="ckpt.pt")
generator = load_csm_1b(model_path, "cuda")
speakers = [0, 1, 0, 0]
transcripts = [
"Hey how are you doing.",
"Pretty good, pretty good.",
"I'm great.",
"So happy to be speaking to you.",
]
audio_paths = [
"utterance_0.wav",
"utterance_1.wav",
"utterance_2.wav",
"utterance_3.wav",
]
def load_audio(audio_path):
audio_tensor, sample_rate = torchaudio.load(audio_path)
audio_tensor = torchaudio.functional.resample(
audio_tensor.squeeze(0), orig_freq=sample_rate, new_freq=generator.sample_rate
)
return audio_tensor
segments = [
Segment(text=transcript, speaker=speaker, audio=load_audio(audio_path))
for transcript, speaker, audio_path in zip(transcripts, speakers, audio_paths)
]
audio = generator.generate(
text="Me too, this is some cool stuff huh?",
speaker=1,
context=segments,
max_audio_length_ms=30_000,
)
torchaudio.save("audio.wav", audio.unsqueeze(0).cpu(), generator.sample_rate)
이번엔 이런 코드이다. 이 코드를 간략하게 설명하자면.. 이전 대화들의 억양, 목소리, 흐름, 등등을 파악해서 그 목소리를 구현하는 것이다.
코드를 보면 알 수 있는데..
speakers = [0, 1, 0, 0]
transcripts = [
"Hey how are you doing.",
"Pretty good, pretty good.",
"I'm great.",
"So happy to be speaking to you.",
]
audio_paths = [
"utterance_0.wav",
"utterance_1.wav",
"utterance_2.wav",
"utterance_3.wav",
]여기에서 speakers에 있는 것이 위에 잠시 말했던.. speaker인 누가 말하는 화자인지.. 여기에서는 1번이 AI 화자 인 것이다.
그리고 transcripts는 대화 들인데..
간단하게 정리를 해보면
- 대화 : "Hey how are you doing.", 파일 이름 : "utterance_0.wav", 화자 ID : 0
- 대화 : "Pretty good, pretty good.", 파일 이름 : "utterance_1.wav", 화자 ID : 1
- 대화 : "I'm great.", 파일 이름 : "utterance_2.wav", 화자 ID : 0
- 대화 : "So happy to be speaking to you.", 파일 이름 : "utterance_3.wav", 화자 ID : 0
이렇게 정리할 수 있고.. 이게 편하게 알 수 있을 것이다.
이걸 나중에 생성할 때 아까 위에서 설정한 speaker를 1로 설정하고 실행하게 되는데.. 그렇게 하면 이전 대화에 화자 ID의 1번 목소리를 복사해서 흐름에 맞춰 자연스럽게 말하게 된다.
audio = generator.generate(
text="Me too, this is some cool stuff huh?",
speaker=1,
context=segments,
max_audio_length_ms=30_000,
)여기에서 보이는 것 처럼 위에 대화에 따라서 다음 말할 것을 지정해주고.. 몇번 ID의 화자를 복사할 것인지 설정을 해주고 이전 대화 목록들을 저장한 segments를 지정하고 초를 지정해주면 되는데.. 아마 실행이 안될 것이다.
이유는 audio_paths에 진짜 음성 파일이 없기 때문이다..
그래서 음성을 만들거나.. 아니면 직접 목소리를 녹음해서 해보면 된다..
(글 쓸 시간이 부족해서.. 따로 해본것은 적지 않겠다. 직접 해보시길..!)
암튼 그렇다.
결론
위에서 예시를 봤듯이..
이건 데모 처럼 실시간 음성 대화 모델은 아닌 것 같다..
아직 모델이 1B 밖에 풀리지 않았고 추가적인 코드가 풀리지 않았기에.. 바로 말하기는 어렵지만..
현재 공개된 코드에서는.. 음성 대화 모델은 아닌 느낌이다..
솔직히 그냥 TTS 모델 같다.
그냥 대화를 지정하고 그것에 맞춰서 말하게 하는 Zero Shot TTS 모델으로 생각된다.
이런 TTS 모델은 이미 다른 곳에서도 개발되고 연구되었기에.. 실시간 음성 대화 모델이 공개로 풀리지 않는 이상..
이 모델을 사용해야하는 이유는 딱히 없다고 생각된다..
그리고 일반 GPU에서 이정도 속도이면.. 너무 느리기도 하고..
암튼.. 이번 모델은 약간 아쉽다..
암튼 그렇다.
그리고 모델 크기는 크기 때문에 한번 사용하고 나면 지우는걸 추천한다. (컴퓨터 용량 크면 딱히 상관은 없지만..)
기본 모델 설치 경로는 아래로 가면 된다.
- Windows : C:\Users\<컴퓨터이름>\.cache\huggingface\hub
- WSL : /home/<컴퓨터이름>/.cache/huggingface/hub
저거 폴더 그냥 지우면 된다.
암튼 끝!